XSLT
XSL-FO による自動組版を行なうには、XSLT と XSL-FO という別々の技術を必要とします。
ここでは、XSLT を開発する上での留意点については、あまり触れません。
原稿記述に XHTML を利用するときに、XSLT で気をつけるべき事柄をひとつだけ述べておきます。
XHTML で、きめ細かな制御を行なおうと思ったら、class 属性を多用せざるを得ません(別の名前空間の XML を利用する方法もありますが)。
class 属性は、ひとつの属性値に複数を指定できるので、
<p class="first keepnext">
などと記述できます。
これを次のように処理したとします。
<xsl:if test="contains(@class,'first')">
...
</xsl:if>
<xsl:if test="contains(@class,'keepnext')">
...
</xsl:if>
これは、単純に class 属性値中に first という文字列が含まれているか否かという判定でしかありません。
例えば、
<p class="foo bar">…
<p class="foobar">…
のような場合、
<xsl:if test="contains(@class,'foo')">
ではうまくいきません。
XSLT 1.0(というか XPath 1.0)の文字列処理は非常に貧弱なため、このような文字列の正確な分割処理(字句解析)はほぼできないので、class名には、部分一致しないものを付けておくのが無難です。
XPath 2.0 では、正規表現が使えたり字句解析ができたりするので、正確に判定できますが、XSLT はもう少し複雑になります。
上のように単純にできるなら、その方がよいでしよう。
<xsl:for-each select="tokenize(normalize-space(@class), ' ')">
...
</xsl:for-each>
XSL-FO
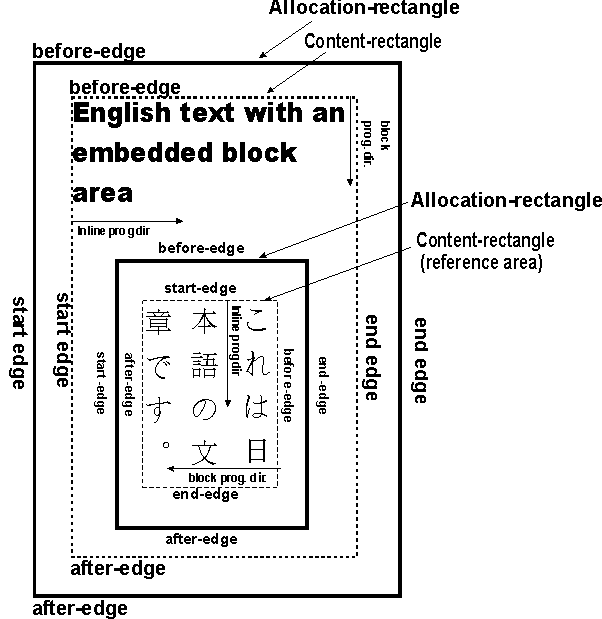
XSL-FO の組版のモデルは、ページの中に長方形の領域を作り、その中に内容を流し込むというものです(領域モデル)。
次の図は、XSL 1.1 からの引用です。
このように、いろいろな領域が入れ子になって配置されている、と考えればよいです。
テキストは、領域をあふれたところで折り返され、その行の高さ分送られて次の行の端から埋められていきます。
XSL-FO は、レイアウトは規定するけれども、禁則処理はどのようにすべきかとか、どこでハイフネーションすべきかとかいうようなことまでは規定していません。
これらは、XSL Formatter のような XSLプロセッサが都合のよいように実装することになります。
XSL Formatter は、文字の性質に関する部分を Unicode仕様に従っています。
禁則処理、行分割処理については Unicode Standard Annex #14: Line Breaking Properties(UAX#14)にほぼ従っています。
XSL-FO のレイアウト指定能力は、(すったもんだしている CSS3 はともかく)現在の CSS2 よりも優れています。
だからといって、XSL-FO は万能ではありません。日本語組版に限らず、不足している機能がいくらかあります。
代表的なものは、段抜きと脚注でしょう。
XSL-FO では、段抜きは全段抜きしかできません。
脚注は、全段抜き脚注しかありません。各段末に脚注を配置することはできません。頭注や傍注といった構造もありません。これらは他の構造で代用することになります。
XSL Formatter は、XSL-FO に不足する多くの機能を独自に拡張し、実装しています。
それだけではただのローカル仕様になってしまうため、W3Cへ提案し、これらの拡張が標準仕様となるように働きかけています。いくつかは、XSL 1.0 から XSL 1.1 への段階で取り入れられています。
段配置の脚注については、XSL Formatter では拡張済みです。傍注といった概念も導入済みです。
部分段抜きは、XSL Formatter でもできません。拡張予定にはなっています。
これらを踏まえた上で、XSL-FO による組版を行なうと、それなりの体裁に組み上がります。
XSL-FO の多くのプロパティ値のデフォルトは、「何もしない」とか「ゼロ」とかです。つまり、何かしたければほとんどすべてのプロパティを明示的に指定してやる必要があります。
また、どのプロパティがどのように継承されていくのかはきちんと理解しておく必要があります。
例えば、
<fo:block font-size="12pt">
<fo:block>
いろはにほへと
</fo:block>
<fo:block>
ちりぬるを
</fo:block>
</fo:block>
というような場合、内側のブロックにも外側のフォントサイズが適用されるということです。
継承でもっとも陥りやすいのが、マージンやインデントなどの継承の問題です。
<fo:block start-indent="1em">
Hello World!
<fo:table>
<fo:table-body>
<fo:table-row>
<fo:table-cell>
<fo:block>
CELL-1
</fo:block>
</fo:table-cell>
<fo:table-cell>
<fo:block>
CELL-2
</fo:block>
</fo:table-cell>
</fo:table-row>
</fo:table-body>
</fo:table>
</fo:block>
外側のブロックにあるインデントの指定は、テーブルセルの内側のブロックにまで継承されます。
そのため、各セルにインデントが取られることになります。(下線はアキを表わしています)
__Hello World!
____CELL-1__CELL-2
多くの場合、これは意図した結果ではありません。
これを回避するためには、
<fo:block start-indent="1em">
Hello World!
<fo:table>
<fo:table-body start-indent="0pt">
<fo:table-row>
...
のようにして継承を断つ必要があります。これによって、次のような結果となります。
__Hello World!
__CELL-1CELL-2
ちょっと考えればわかることですが、ここに、<fo:table> に指定しているのではないことに注意してください。
<fo:table start-indent="0pt"> としてしまうと、テーブル自身への指定となるので、次のようになります。
__Hello World!
CELL-1CELL-2
さらに面倒なのが、margin-* というプロパティです。margin-left や margin-top などのプロパティは、CSS から持ち込まれたプロパティで、XSL-FO では、他のプロパティに変換されます。
例えば、margin-left からは start-indent が計算されて、それが保持されます。
<fo:block margin-left="1em">
Hello World!
<fo:table>
<fo:table-body margin-left="0pt">
<fo:table-row>
...
このような指定では、セルのインデントは打ち消すことができません。
この例では border や padding が指定されていないので、ごく単純に、margin-left="1em" は、start-indent="1em" に変換されます。<fo:table-body margin-left="0pt"> では、継承された start-indent が考慮されて、結果としてそこでの start-indent は 1em のままとなります(詳細は XSL 1.1 の 5.3.2 を参照してください)。
このような小難しいことを避けるために、margin-* は使わずに、start-indent や padding-* などのプロパティを利用することを勧めます。
XSL-FO の継承では、参照領域の考えをよく理解しておく必要があります。
また、空白の扱いもよく理解しておかなければなりません。
CSS に慣れた人は、そのモデルの違い(CSS のボックスモデル、XSL の領域モデル)にも注意する必要があります。
CSS では、border や padding は指定されているボックスの内側に取られますが、XSL では領域の外側に取られます。
「Open Office XML Formats入門」で最後まで調整していたのは、次のような部分です。
widow、orphan は、(わざわざ無効にしていなければ)普通に行なわれるので問題とはなりません。
ここでは、ただ1行の段落がページ末に位置し、それが次の図や表を指す場合です。
この例のような、互いに関連しているブロックには、分離を制限するプロパティを付けておく必要があります。
例えば、原稿XMLでは、次のように何か印を付けることを行ないます。
<p>
…なんとかかんとかです。
</p>
<p class="keepnext">
次の図を参照してください。
</p>
<p>
<img .../>
</p>
これを XSLT で処理して、次のような XSL-FO に変換します。
<fo:block>
…なんとかかんとかです。
</fo:block>
<fo:block keep-with-next.within-page="always">
次の図を参照してください。
</fo:block>
<fo:block>
<fo:external-graphic .../>
</fo:block>
あるいは、次のようにもできます。
<fo:block>
…なんとかかんとかです。
</fo:block>
<fo:block keep-together.within-page="always">
<fo:block>
次の図を参照してください。
</fo:block>
<fo:block>
<fo:external-graphic .../>
</fo:block>
</fo:block>