OCRオプションの設定
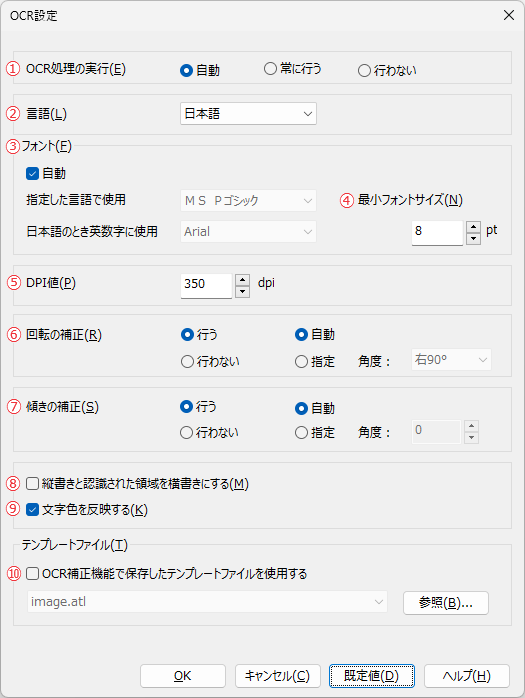
図3・60 「OCR設定」ダイアログボックス
- ① OCR処理の実行
- OCR処理の方法を以下のいずれかで設定します。
- 自動:PDFファイルのページ毎にOCR処理を行うかどうかを判断しながら処理します。ページ上に文字データが存在する場合には、OCR処理を行なわず通常の変換処理を行います。
この場合、画像データは画像のまま変換先に移ります。また、ページ上に画像データだけしか存在しない場合にはOCR処理を行います。この場合、OCR処理による文字認識で文字が出力されます。
 【ヒント】
【ヒント】
通常は[自動]を選択してください。
- 常に行う:PDFを画像データとして扱い強制的にOCR処理を実行します。この場合、PDFのページ内で文字と認識できるデータは通常の文字として出力されます。
【ヒント】
PDF内部に文字が埋め込みされていて文字コードとの関連づけがない場合、通常の変換では文字化けしてしまいます。そのような場合、OCRを常に行う設定にすることで文字に変換することができます。
- 行わない:OCR処理を行いません。PDFファイルのページ中の画像はそのまま出力されます。
 【注意!】
【注意!】
変換先に「OCR」を選択した場合やOCR補正機能を選択した場合は、設定に関わらず常にOCR処理が行われます。
- ② 言語
- OCR処理対象となる文書の言語を指定します。元データ中に指定された言語以外の文字があると文字化けや誤変換が生じる場合があります。
表3・2 指定可能な言語
| 言語 | 自動で設定されるフォント |
| 日本語 | MS Pゴシック(和文)、Arial(英数字) |
| 英語 | Times New Roman |
| ドイツ語 | Times New Roman |
| フランス語 | Times New Roman |
| スペイン語 | Times New Roman |
| イタリア語 | Times New Roman |
| スウェーデン語 | Times New Roman |
| デンマーク語 | Times New Roman |
| ノルウェー語 | Times New Roman |
| オランダ語 | Times New Roman |
| ポルトガル語 | Times New Roman |
| チェコ語 | Times New Roman |
| ハンガリー語 | Times New Roman |
| ポーランド語 | Times New Roman |
| ルーマニア語 | Times New Roman |
| スロバキア語 | Times New Roman |
| クロアチア語 | Times New Roman |
| スロベニア語 | Times New Roman |
| ルクセンブルク語 | Times New Roman |
| フィンランド語 | Times New Roman |
| リトアニア語 | Times New Roman |
| ラトビア語 | Times New Roman |
| トルコ語 | Times New Roman |
| カタルーニャ語 | Times New Roman |
| ブルガリア語 | Times New Roman |
| マケドニア語 | Times New Roman |
| ロシア語 | Times New Roman |
| セルビア語 | Times New Roman |
| ウクライナ語 | Times New Roman |
| ギリシャ語 | Times New Roman |
| ベトナム語 | Times New Roman |
| タイ語 | Tahoma |
| 韓国語 | Malgun Gothic |
| 簡体字中国語 | SimSun |
| 繁体字中国語 | Microsoft JhengHei |
【ヒント】
- 既定の言語は[日本語]です。
- 日本語以外で記述されたPDFを[日本語]モードで変換すると、文字によっては誤変換する場合があります。そのようなときは記述された言語に切り替え、言語に適したフォントを指定してください。
- ③ フォント
- 指定した言語に用いるフォントを実行環境にインストールされたフォントの一覧から指定します。言語を日本語に指定した場合は、元データ中のアルファベットと数字のみ別のフォントに指定できます。言語を変更した場合は、その言語に対応した適切なフォントを指定してください。
【ヒント】
OCR処理を使用した変換では、変換結果の文字列に対して一括で指定したフォントが適用されます。このため、元データ中に複数の言語が混在しているような場合は、指定した言語以外の文字が正しく変換されません(日本語、韓国語または中国語と英語が混在した場合を除く)。
- ④ 最小フォントサイズ
- OCR処理では画像から認識した文字の大きさでフォントサイズを決定しますが、解像度などの条件により文字が実際より小さいサイズに認識されることがあります。そのような場合、小さなフォントサイズを一定の大きさに揃えることで編集しやすくできます。
- ここで指定したサイズ以下の文字は、最小フォントサイズで出力します。
変換形式として「OCR結果をPDFファイルに埋め込む」が選択されている場合、これらの設定は無視されます。
- ⑤ DPI値
- 本製品では、OCR処理を行う際に対象となるページをビットマップ画像に変換します。ここで設定するDPI値はこのとき作成する画像の解像度として参照されます。96~500(dpi)の範囲で設定します。
【ヒント】
一般的に解像度が低いと文字の認識率は低下し、解像度が高いと認識率は高くなります。しかし、高解像度に設定した場合、画像作成に長時間かつ大量のメモリーを必要とするため、場合によっては処理に失敗する可能性もあります。通常は、300~400dpiの範囲を指定してください。
- ⑥ 回転の補正
- 処理対象となるページの向きが回転している場合、これを補正できます。
- 行う:回転補正を行います。
- [自動]を選択した場合、OCR処理の際に自動的にページの回転方向を判断します。但し、画像の状態によりページの回転方向を正しく判断できない場合があります。
- [指定]を選択した場合、回転補正角度をラジオボタン右のコンボボックスを使って、[右90°]/[左90°]/[180°]のいずれかで指定します。
- 行わない:回転補正を行いません。
- ⑦ 傾きの補正
- 処理対象となるページが傾いている場合、これを補正できます。通常は、「自動」を選択します。
- 行う:傾き補正を行います。補正を自動で行うか、±45°の範囲を1°単位で指定して行うか指定できます。
- 行わない:傾き補正を行いません。
【注意!】
ここで設定した回転・傾き角度は、すべてのページに一括適用します。任意のページのみ設定したい場合は、別途、OCR補正機能を使用し、ページ単位に回転・傾き角度を指定してください。
- ⑧ 縦書きと認識された領域を横書きにする
- 処理対象となるページが横書きであるにも関わらず、文字の並び位置が縦方向に揃っていると縦書きの領域と誤認されることがあります。このような場合に強制的に横書きの領域に変更できます。
領域の変更は、[OCR補正機能]を使うとファイル毎に手動で指定できます。
- ⑨ 文字色を反映する
- 既定値では、画像データをカラーで処理して文字色などを変換先に反映しますが、画像データによっては白黒2値画像にしてOCR処理することで認識精度が改善する場合があります。OCRの結果が芳しくないと思われるときは、この設定をOFFにしてみてください。
【注意!】
- この設定をオフにして変換した場合は色の情報が失われ文字色がすべて黒に変換されます。
- 設定の切り替えはOCR処理の認識精度に影響するため、変換結果が同じにならない場合があります。
【ヒント】
OCR処理では、画像上でテキストや表として変換したい部分を別の領域として誤認識してしまう場合があります。本製品の既定値ではそのようなときに誤認識したままOCR処理を行うため、文字化けなどが生じてしまいます。
このような場合は、[OCR補正機能]を使用すると、画面上の操作により誤認識した領域を正しい領域に補正できます。
- ⑩ OCR補正機能で保存したテンプレートファイルを使用する
- テンプレートファイル(*.atl)を読み込む場合は、チェックをつけてください。ここにチェックをつけることで、テンプレートファイル名の指定が可能になります。
- テンプレートファイル名:お使いのパソコンにテンプレートファイル(*.atl)が保存されている場合には、ここにファイルの一覧が表示されます。一覧から任意のファイルを選択してください。
図3・61 テンプレートファイルの指定
関連...