2.1.2 指定した画像を抽出
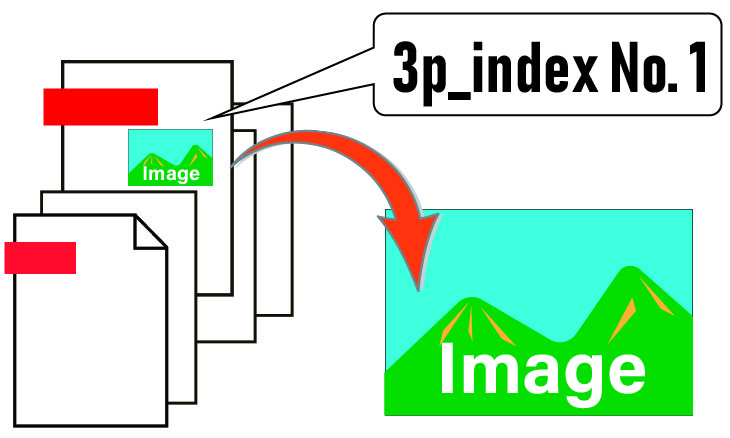
狙い・効果
画像の抽出指定されたページ内の指定されたインデックス番号の画像を書き出します。
処理の概要
ページ番号と画像のインデックス番号を入力して、指定された画像を画像ファイルとして書き出します。出力のフォルダパスとファイル名(ボディ部)は入力時に指定する必要があります。画像形式は自動で決定され、拡張子がボディ部に付けられた状態で出力されます。
『PDF Tool API』の主な機能
PtlEditElements.APIget(int index): indexと一致する番号のEditElementを取得
PtlEditElement: コンテントに描画されるエレメントを表現したクラス。すべてのエレメントクラスのベースクラス
PtlEditImage: コンテントに描画される画像を表現したクラス
PtlEditImage.APIwriteFile(PtlParamOutput output, PtlEditImage.OUTPUT_FORMAT format): PtlParamOutputで指定したパスに画像を書き出す
プログラム例
package cookbook;
import jp.co.antenna.ptl.*;
public class ExtractImageSimple {
// そのクラスのusageを表示する関数
private static void printUsage(){
System.out.println("usage: java ExtractImageSimple in-pdf-file out-image-body" +
" page-to-extract image-index-num");
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 4) {
printUsage();
return;
}
// コマンドライン引数の取得
int pageToExtract = Integer.parseInt(args[2]);
int imageIndexNum = Integer.parseInt(args[3]);
try (PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument()) {
// PDFファイルをロードします。
doc.load(inputFile);
try (PtlPages pages = doc.getPages()) { // ページコンテナの取得
// ページコンテナが空かどうか
if (pages.isEmpty()) {
System.out.println("ページコンテナが空");
return;
}
// それ以外であれば指定ページ番号を検索。
int wholePageNum = doc.getPageCount();
//pageToSearchのエラー処理
if(wholePageNum < pageToExtract) {
System.out.println("ERROR: page-to-extractはPDFの総ページ数より"+
"小さい値を指定してください。");
System.out.println("総ページ数:" + wholePageNum);
printUsage();
return;
}
// ページの取得(index番号は0が先頭のため1を引く)
try (PtlPage page = pages.get(pageToExtract - 1)) {
// 画像抽出
extractImageSimple(page, args[1], imageIndexNum);
}
}
}
...【ExtractText.javaと同じ処理のため省略
・エラーメッセージ処理と出力】...
}
public static void extractImageSimple(PtlPage page, String imagefileName,
int imageIndexNum)
throws PtlException, Exception, Error {
// ページコンテント・画像エレメントの取得
try (PtlContent content = page.getContent();
PtlEditElements elems = content.getEditElements(PtlContent.GET_IMAGE)) {
int numElems = elems.getCount();
if (numElems == 0) {
System.out.println("指定されたページに画像エレメントがありませんでした。");
return; // 画像エレメントが無い場合はreturnする
}
//imageIndexNumのエラー処理
if(numElems < imageIndexNum) {
System.out.println("ERROR: image-index-numは対象ページの総画像数より"+
"小さい値を指定してください。");
System.out.println("総画像数:" + numElems);
printUsage();
return;
}
// OUTPUT_FORMATはFORMAT_AUTOで設定。
PtlEditImage.OUTPUT_FORMAT format = PtlEditImage.OUTPUT_FORMAT.FORMAT_AUTO;
// 画像エレメントの取得
try (PtlEditElement elem = elems.get(imageIndexNum - 1)) {
PtlEditElement.ELEMENT_TYPE type = elem.getType();
switch (type) {
case TYPE_IMAGE:
PtlEditImage elemImage = (PtlEditImage)elem;
try (PtlParamOutput outputImage = new PtlParamOutput(imagefileName)) {
// 画像出力
elemImage.writeFile(outputImage, format);
}
break;
default:
System.out.println("指定されたエレメントは画像ではありません。");
break;
}
}
}
}
}
プログラムファイル名
ExtractImageSimple.java
入出力操作の例
C:\samples>java cookbook.ExtractImageSimple usage: java ExtractImageSimple in-pdf-file out-image-body page-to-extract image-index-num C:\samples>java cookbook.ExtractImageSimple colorImg.pdf outputImgSimple 1 2 -- 完了 --

colorImg.pdfファイルの1ページには二つの画像があり、その2番目の画像を抽出します。