3.1.4 挿入したテキストの取得(テキストボックス)
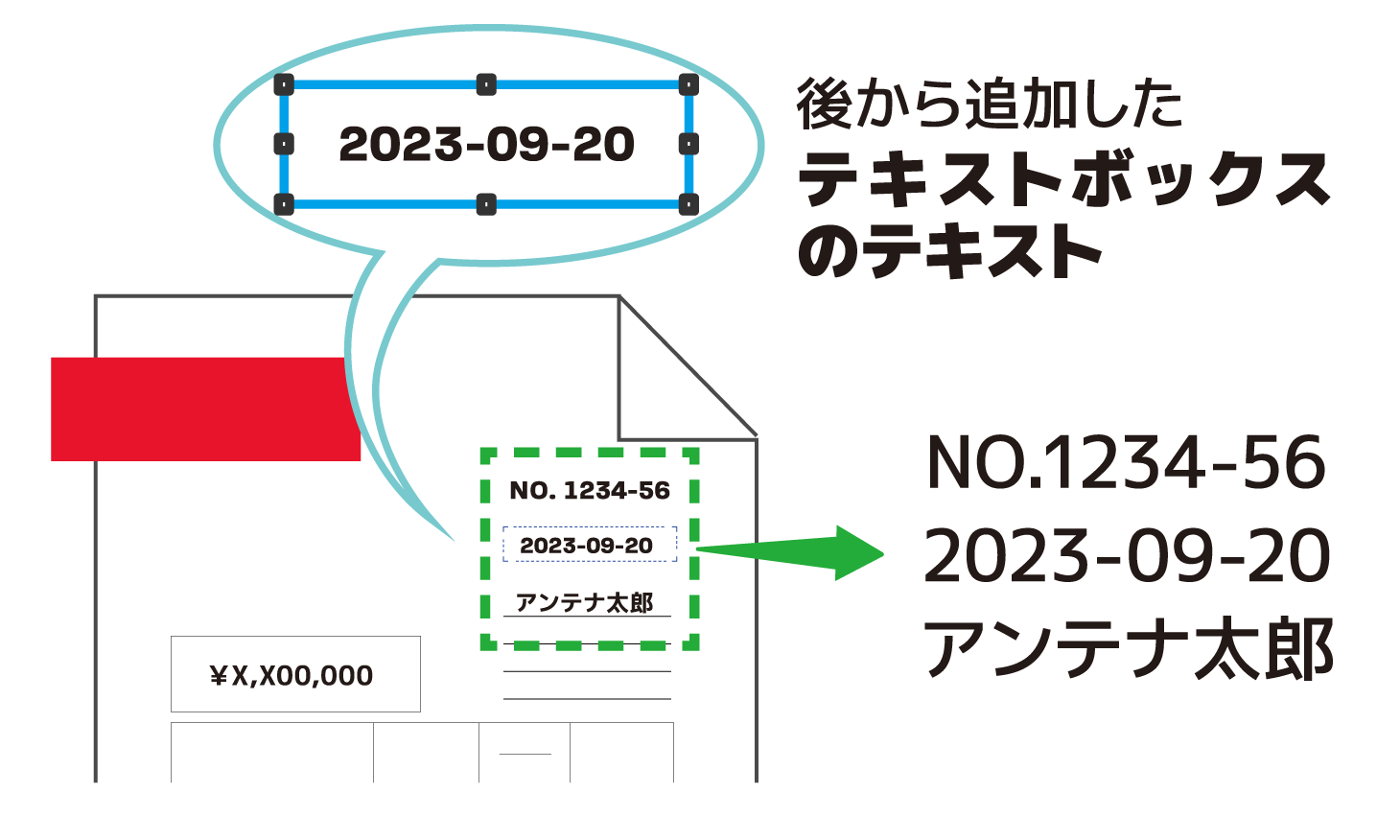
狙い・効果
テキストボックスで描画したテキストを抽出します。
処理の概要
テキストボックスで描画したテキストはその他のテキストと同様に、PtlContent. extractText()を用いて抽出できます。
本プログラムでは、「『PDF CookBook』(第3巻)1.1.2 指定矩形からテキストを抽出」で紹介したサンプルプログラムを用いてテキストボックスと同じ矩形を指定して、設定されているテキストを抽出します。
『PDF Tool API』の主な機能
- PtlContent.extractText(PtlParamExtractText): テキストを抽出
- PtlParamExtractText.appendRect(PtlRect rectMM): テキスト抽出する矩形を追加
- PtlParamExtractText.setTextOverlapRatio(float overlapRatio): テキストが矩形とどれくらい重なっていたら抽出対象とするかを設定
プログラム例
package cookbook;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.BufferedWriter;
import java.io.PrintWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.charset.StandardCharsets;
import jp.co.antenna.ptl.*;
public class ExtractTextSetRect {
// そのクラスのusageを表示する関数
private static void printUsage() {
System.out.println("usage: java ExtractTextSetRect in-pdf-file out-text-file" +
" page-to-extract overlap-ratio ignore-actual-text");
System.out.println("ignore-actual-text:");
System.out.println("0:ActualTextを無視しない 1:ActualTextを無視する");
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 5) {
printUsage(); // usageメッセージの表示
return;
}
// コマンドライン引数の読み取り・判定
// 出力PDFの名前はあとで渡すためにString型で保存する。
String outputTextURI = args[1];
int pageToExtract = Integer.parseInt(args[2]);
float overlapRatio = Float.parseFloat(args[3]);
boolean ignoreActualText = true;
try {
ignoreActualText = readBoolArgs(args[4],
"ignore-actual-textは1か0で指定してください。");
}
catch (IllegalArgumentException ex) {
System.out.println(ex.getMessage());
printUsage(); // usageメッセージの表示
return;
}
try (PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument();
BufferedReader br = new BufferedReader(new InputStreamReader(System.in))) {
// PDFファイルをロード
doc.load(inputFile);
//ページ数を取得
int wholePageNum = doc.getPageCount();
//pageToExtractのエラー処理
if(wholePageNum < pageToExtract) {
System.out.println("ERROR: page-to-extractはPDFの総ページ数より"+
"小さい値を指定してください。");
System.out.println("総ページ数:" + wholePageNum);
printUsage();
return;
}
try (PtlPages pages = doc.getPages()) {//ページコンテナの取得
// ページコンテナが空かどうか
if (pages.isEmpty()) {
System.out.println("ERROR : ページコンテナが空");
return;
}
// ページの取得(パラメータindexは0が先頭のため1を引く)
try (PtlPage page = pages.get(pageToExtract - 1);
// ページコンテントの取得
PtlContent content = page.getContent();
// 文字抽出のパラメータクラス。
PtlParamExtractText paramExtractText = new PtlParamExtractText();
PtlRect outputRect = new PtlRect()) {
// テキスト抽出する矩形を指定
paramExtractText.appendRect(setRectCoordinate(br, outputRect));
// テキストが矩形とどのくらい重なっていれば抽出するか設定
paramExtractText.setTextOverlapRatio(overlapRatio);
// ActialTextを無視するかどうか
paramExtractText.setIgnoreActualText(ignoreActualText);
// 文字列抽出
String TextFromPdf = content.extractText(paramExtractText);
// 文字列の出力
outputTextFile(outputTextURI, TextFromPdf);
System.out.println(TextFromPdf);
}
}
}
...【GetPDFVersion.javaと同じ処理のため省略
・エラーメッセージ処理と出力】...
}
/**
* テキストファイルを出力するための関数。
* 出力エンコードはUTF-8を指定する。
* 特に外部からの呼び出しを想定しないためprivateとする。
*
* @param outputTextURI 出力ファイルのURI。
* @param TextFromPdf 出力したいString型変数
*/
private static void outputTextFile(String outputTextURI, String TextFromPdf) {
System.out.println("Output text URI :" + outputTextURI);
try(BufferedWriter bw = Files.newBufferedWriter(Paths.get(outputTextURI),
StandardCharsets.UTF_8);
PrintWriter pw = new PrintWriter(bw, false)) {
pw.print(TextFromPdf);
}
catch(IOException e) {
System.out.println("IOException occured!!");
e.printStackTrace();
}
}
/**
* 矩形の各値を入力してその座標値をもつ矩形を返す関数。
* 原点はPDFの左下端。
* bottomよりtopが大きい、leftよりもrightが大きいなどの矛盾した数値は入力できない。
* 特に外部からの呼び出しを想定しないためprivateとする。
* @param br BufferedReader。数値の読み取りに使う。
* @return 指定したleft, bottom, right, topの数値を持つPtlRect
* @throws IOException
* @throws PtlException
* @throws Exception
* @throws Error
*/
public static PtlRect setRectCoordinate(BufferedReader br, PtlRect outputRect)
throws IOException, PtlException, Exception, Error {
...【TBoxDrawTextBox.javaと同じ処理のため省略
・[top, bottom, left, right]を設定し、PtlRect型変数を返す関数】...
}
/**
* 0または1を入力されたargsにより、trueまたはfalseを返すメソッド。
*
* @param args 与えられるコマンドライン引数。0または1でtrueまたはfalseを指定する。
* @param errorMessage argsが0か1でなかった場合に出力されるエラーメッセージを指定する。
* @return argsの数値を読み取った結果を戻す
* @throws java.lang.IllegalArgumentException argsが0か1でなかった場合に発生。
*/
public static boolean readBoolArgs(String args, String errorMessage)
throws IllegalArgumentException {
...【FixUpPDFASetSaveOption.javaと同じ処理のため省略
・0または1を読み取り、boolean型のfalseまたはtrueを返す関数】...
}
}
プログラムファイル名
ExtractTextSetRect.java
入出力操作の例
C:\samples>java cookbook.ExtractTextSetRect usage: java ExtractTextSetRect in-pdf-file out-text-file page-to-extract overlap-ratio ignore-actual-text ignore-actual-text: 0:ActualTextを無視しない 1:ActualTextを無視する C:\samples>java cookbook.ExtractTextSetRect Output_TBoxDrawTextBox.pdf Output_ExtractTextSetRect.txt 1 0.6 1 指定する矩形の各数値を入力してください。 top (mm) : 120 bottom (mm) : 80 left (mm) : 50 right (mm) : 130 Output text URI :Output_ExtractTextSetRect.txt これは、テキストボックスの入力文章です。このようにテキストボックスに入力された文章は折り返されます。 -- 完了 --
この操作例ではPDFの左下隅を基準に、左下頂点(50mm, 80mm)、右上頂点(130mm, 120mm)の矩形を指定してテキストを抽出・取得しています(図3.4)。図3.5が抽出されたテキストです。

図3.4 PDFでテキスト抽出された箇所。赤点線で示されている矩形が指定座標の範囲
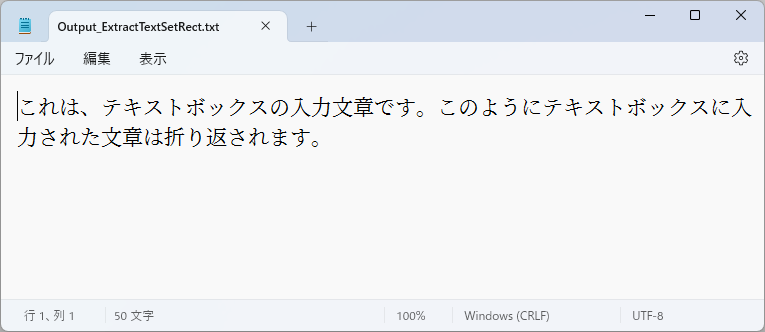
図3.5 テキストファイル内容。文面がテキストと一致している