5.2.1 PDFにExif付きJPEG画像を埋め込み、元の画像のまま抽出する

狙い・効果
PDFに画像埋め込まれたJPEG画像を加工せずに出力するかどうかを指定します。
処理の概要
PDFに描画されたJPEG画像をJPEG指定して書き出す際に、再圧縮せずにそのまま出力するオプションを選択できます。
setPathThrough()を指定することで、埋め込まれたJPEG画像を埋め込まれた条件の画像のまま抽出することができるオプションです。例えば、PDFにExif情報を持ったJPEG画像が埋め込まれていたとき、Exif情報抽出した画像からExif情報を読み取ることができます。
また、『PDF Tool API』を含め多くのソフトウェアではPDF変換の際、画像は再圧縮して埋め込むという設定をデフォルトにしています。JPEG画像が埋め込み時に再圧縮をされていると、PDF変換前の埋め込み元画像の取り出しはできません。例えばExif付き画像をPDFに埋め込んだ後、そのままの形で取り出したいときは、PDFに画像を埋め込む時点で注意しておく必要があります。
埋め込み時に以下の条件をすべて満たしていた場合は、再圧縮を行わずにJPEG画像のPDF埋め込みが可能です。
- カラースペースが、DeviceRGB, DeviceGray, 無指定(=PDF_EMPTY_NAME)のいずれかで指定されていること
- マスクが指定されていないこと
- Decodeの値がデフォルトであること
- トランスファ関数を表すグラフィックステートパラメータ辞書の『ExtGState:TR』が指定されていないこと(一般にトランスファ関数はガンマ補正の用途で使用される機能です)
サンプルプログラムでは、指定したindex番号の画像を書き出す際にJPEG加工せずにそのまま書き出すかどうかを選択します。
- プログラムの実行サンプルPDFは上記条件を満たす形で用意したExif付き画像を埋め込んでいます。
- そこから抽出したJPEG画像からExif情報が読み取れることを確認します。
『PDF Tool API』の主な機能
- PtlEditImage.setPathThrough(boolean pathThrough): JPEGを加工せずにそのまま出力するどうかを指定。これは画像の出力フォーマットにFORMAT_JPEGを指定した場合にのみ動作します。設定しない場合はデフォルト値としてfalseが設定されます。
プログラム例
package cookbook;
import jp.co.antenna.ptl.*;
public class ExtractImageSetPassthrough {
// そのクラスのusageを表示する関数
private static void printUsage() {
System.out.println("usage: java ExtractImageSetPassthrough in-pdf-file out-image-body" +
" page-to-extract image-index-num set-passthrough");
System.out.println("set-passthrough : ");
System.out.println("0 : JPEG圧縮する 1 : JPEGは加工せずにそのまま出力する");
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 5) {
printUsage();
return;
}
// コマンドライン引数の取得
int pageToExtract = Integer.parseInt(args[2]);
int imageIndexNum = Integer.parseInt(args[3]);
boolean setPassthrough = false;
try {
setPassthrough = readBoolArgs(args[4], "set-passthroughは 0か1で指定してください。");
}
catch (IllegalArgumentException ex) {
System.out.println(ex.getMessage());
printUsage(); // usageメッセージの表示
return;
}
try (PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument()) {
// PDFファイルをロードします。
doc.load(inputFile);
try (PtlPages pages = doc.getPages()) { // ページコンテナの取得
// ページコンテナが空かどうか
if (pages.isEmpty()) {
System.out.println("ページコンテナが空");
return;
}
// それ以外であれば指定ページ番号を検索。
int wholePageNum = doc.getPageCount();
//pageToSearchのエラー処理
if(wholePageNum < pageToExtract) {
System.out.println("ERROR: page-to-extractはPDFの総ページ数より"+
"小さい値を指定してください。");
System.out.println("総ページ数:" + wholePageNum);
printUsage();
return;
}
// ページの取得(index番号は0が先頭のため1を引く)
try (PtlPage page = pages.get(pageToExtract - 1)) {
// 画像抽出
extractImageSetPassthrough(page, args[1], imageIndexNum, setPassthrough);
}
}
}
...【GetPDFVersion.javaと同じ処理のため省略
・エラーメッセージ処理と出力】...
}
public static void extractImageSetPassthrough(PtlPage page, String imagefileName,
int imageIndexNum, boolean setPassthrough)
throws PtlException, Exception, Error {
// ページコンテント・画像エレメントの取得
try (PtlContent content = page.getContent();
PtlEditElements elems = content.getEditElements(PtlContent.GET_IMAGE)) {
int numElems = elems.getCount();
if (numElems == 0) {
System.out.println("指定されたページに画像エレメントがありませんでした。");
return; // 画像エレメントが無い場合はreturnする
}
//imageIndexNumのエラー処理
if(numElems < imageIndexNum) {
System.out.println("ERROR: image-index-numは対象ページの総画像数より"+
"小さい値を指定してください。");
System.out.println("総画像数:" + numElems);
printUsage();
return;
}
// 画像エレメントの取得
try (PtlEditElement elem = elems.get(imageIndexNum - 1)) {
PtlEditElement.ELEMENT_TYPE type = elem.getType();
switch (type) {
case TYPE_IMAGE:
PtlEditImage elemImage = (PtlEditImage)elem;
elemImage.setPathThrough(setPassthrough);
try (PtlParamOutput outputImage = new PtlParamOutput(imagefileName)) {
// 画像出力(パススルー設定を確かめるため、FORMAT_JPEGで出力する。)
elemImage.writeFile(outputImage, PtlEditImage.OUTPUT_FORMAT.FORMAT_JPEG);
}
break;
default:
System.out.println("指定されたエレメントは画像ではありません。"
+ "処理を中断します。");
break;
}
}
}
}
/**
* 0または1を入力されたargsにより、trueまたはfalseを返すメソッド。
*
* @param args 与えられるコマンドライン引数。0または1でtrueまたはfalseを指定する。
* @param errorMessage argsが0か1でなかった場合に出力されるエラーメッセージを指定する。
* @return argsの数値を読み取った結果を戻す
* @throws java.lang.IllegalArgumentException argsが0か1でなかった場合に発生。
*/
public static boolean readBoolArgs(String args, String errorMessage)
throws IllegalArgumentException {
...【FixUpPDFASetSaveOption.javaと同じ処理のため省略
・0または1を読み取り、boolean型のfalseまたはtrueを返す関数】...
}
}
プログラムファイル名
ExtractImageSetPassthrough.java
入出力操作の例
C:\samples>java cookbook.ExtractImageSetPassthrough usage: java ExtractImageSetPassthrough in-pdf-file out-image-body page-to-extract image-index-num set-passthrough set-passthrough : 0 : JPEG圧縮する 1 : JPEGは加工せずにそのまま出力する C:\samples>java cookbook.ExtractImageSetPassthrough SampleImage_witExif.pdf Output_ExtractImageSetPassthrough.jpg 1 1 1 -- 完了 --
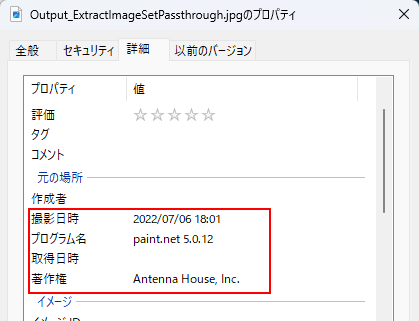
図5.2 抽出したJPEG画像から読み取れるExif情報の例