9.2.1 重なり合う同じ文字を除外して抽出する
狙い・効果
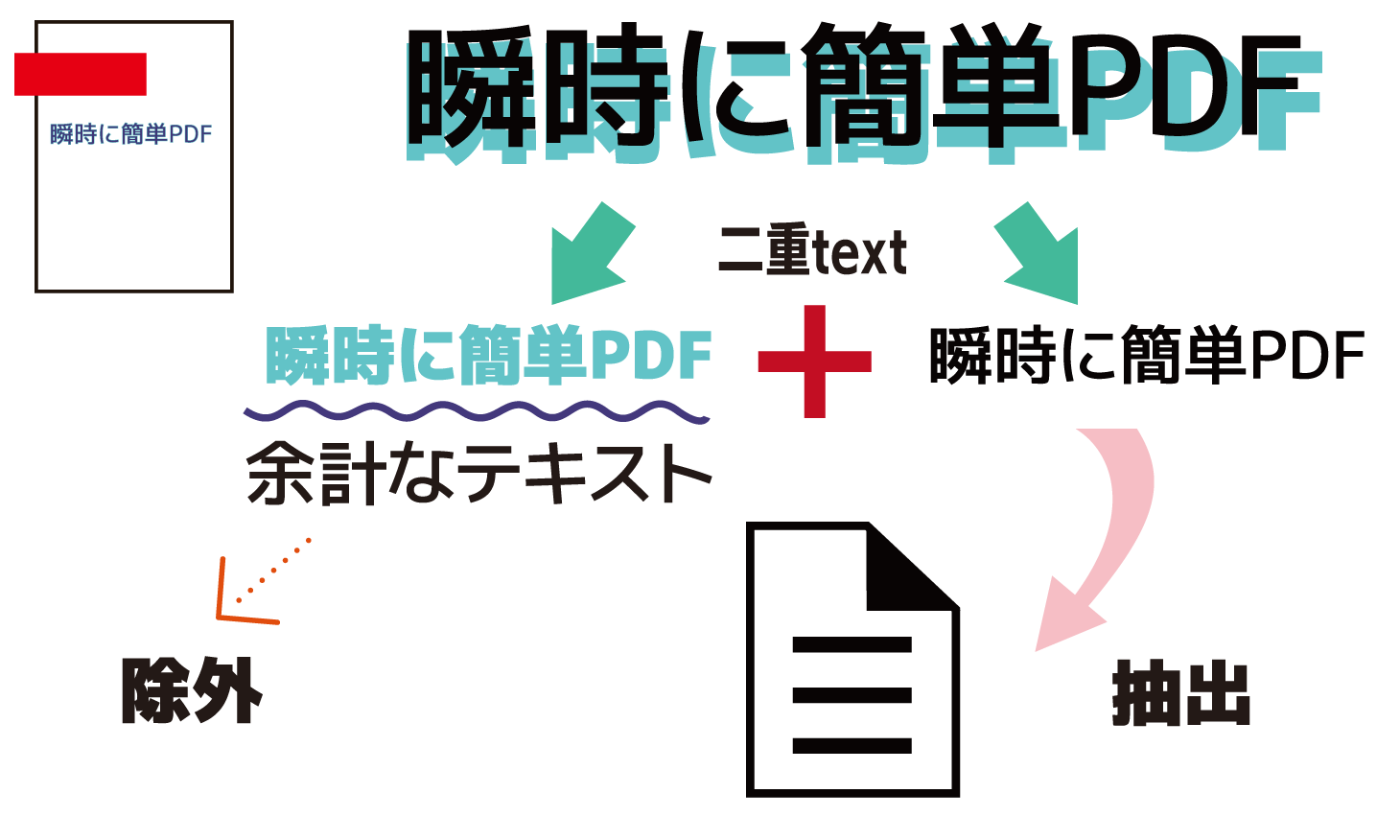
文字抽出文字抽出の際に重なりあっている同じ文字を除外します。
処理の概要
文字抽出の範囲に重なり合った同じ文字が含まれていた場合に、重なり具合を指定して取り除くことができます。
デザインとして文字に影をつける効果のために同じ文字を重ねていた場合など、同じ文字の二重抽出が防げます。
サンプルプログラムでは、入力PDFの指定したページから文字を抽出する際に、指定した割合以上に重なっている同じ文字を除外して抽出します。
『PDF Tool API』の主な機能
- PtlParamExtractText.setSameTextOmitRatio(float overlap): 同じ文字がどれだけ重なっていると取り除くかを設定。overlapで文字の重なり具合を割合でセット。デフォルト値(0.0)では重なり合っていても取り除かれません。
プログラム例
package cookbook;
import java.io.BufferedWriter;
import java.io.PrintWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.charset.StandardCharsets;
import jp.co.antenna.ptl.*;
public class ExtTextSetSameTextOmitRatio {
// そのクラスのusageを表示する関数
private static void printUsage() {
System.out.println("usage: java ExtTextSetSameTextOmitRatio"
+ " in-pdf-file out-text-file"
+ " page-to-extract sameText-omit-ratio");
System.out.println("sameText-omit-ratio:");
System.out.println("同じ文字が重なり合っていた場合にどの程度重なり合っていたら除外するかを小数で指定");
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 4) {
printUsage(); // usageメッセージの表示
return;
}
// コマンドライン引数の読み取り・判定
// 出力PDFの名前はあとで渡すためにString型で保存する。
String outputTextURI = args[1];
int pageToExtract = Integer.parseInt(args[2]);
float sameTextOmitRatio = Float.parseFloat(args[3]);
try (PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument()) {
// PDFファイルをロード
doc.load(inputFile);
//ページ数を取得
int wholePageNum = doc.getPageCount();
//pageToExtractのエラー処理
if(wholePageNum < pageToExtract) {
...【ExtractTextSetRect.javaと同じ処理のため省略
・指定したページが総ページ数より多い場合のエラー処理】...
}
try (PtlPages pages = doc.getPages()) {//ページコンテナの取得
// ページコンテナが空かどうか
if (pages.isEmpty()) {
System.out.println("ERROR : ページコンテナが空");
return;
}
// ページの取得(パラメータindexは0が先頭のため1を引く)
try (PtlPage page = pages.get(pageToExtract - 1);
// ページコンテントの取得
PtlContent content = page.getContent();
// 文字抽出のパラメータクラス。
PtlParamExtractText paramExtractText = new PtlParamExtractText()) {
// 同じテキストがどのぐらい重なっていたら取り除くかを指定する。
paramExtractText.setSameTextOmitRatio(sameTextOmitRatio);
// 抽出するテキストを座標順に並べるよう指定
//(setSameTextOmitRatioのためには指定が必要)
paramExtractText.setTextType(PtlParamExtractText.TEXT_TYPE.TEXT_SORT);
// 文字列抽出
String TextFromPdf = content.extractText(paramExtractText);
// 文字列の出力
outputTextFile(outputTextURI, TextFromPdf);
System.out.println(TextFromPdf);
}
}
}
...【GetPDFVersion.javaと同じ処理のため省略
・エラーメッセージ処理と出力】...
}
/**
* テキストファイルを出力するための関数。
* 出力エンコードはUTF-8を指定する。
* 特に外部からの呼び出しを想定しないためprivateとする。
*
* @param outputTextURI 出力ファイルのURI。
* @param TextFromPdf 出力したいString型変数
*/
private static void outputTextFile(String outputTextURI, String TextFromPdf) {
...【ExtractTextSetRect.javaと同じ処理のため省略
・outputTextURIのパスにTextFromPDFの内容をUTF-8エンコーディングで出力する処理】...
}
}
プログラムファイル名
ExtTextSetSameTextOmitRatio.java
入出力操作の例
C:\samples>java cookbook.ExtTextSetSameTextOmitRatio usage: java ExtTextSetSameTextOmitRatio in-pdf-file out-text-file page-to-extract sameText-omit-ratio sameText-omit-ratio: 同じ文字が重なり合っていた場合にどの程度重なり合っていたら除外するかを小数で指定 C:\samples>java cookbook.ExtTextSetSameTextOmitRatio sample_overlap_text.pdf Output_ExtTextSetSameTextOmitRatio.txt 1 0.7 Output text URI :Output_ExtTextSetSameTextOmitRatio.txt Overlap Test 01 Overlap Test 02 Overlap Test 03 Overlap Test 03 Overlap Test 04 Overlap Test 04 Overlap Test 05オーバーラップテスト05 Overlap Test 06オーバーラップテスト06オーバーラップテスト07 Overlap Test 07オーバーラップテスト08 Overlap Test 08 OオvーerバlapーTラesッtプ09テスト09 OオvーerバlapーTラesッtプ10テスト10オーバーラップテスト11 Overlap Test 11オーバーラップテスト12 Overlap Test 12 -- 完了 --
今回の操作例では複数の重なり合ったテキストが含まれるPDFから文字を読み取ります。(第2節の操作例ではすべて下図のPDFを使用し、テキスト表示・比較はWindows11標準のメモ帳です)

図9.15 操作例で使われる入力PDF
サンプルプログラムでは、抽出時に同じ文字が一定以上重なり合っているものは読み取りません。
下図はoverlapに0.7を指定した操作例で、テキスト抽出の際大きく重なっていたため二重に読み取られなかった部分とその続きの部分を抜粋したものです。
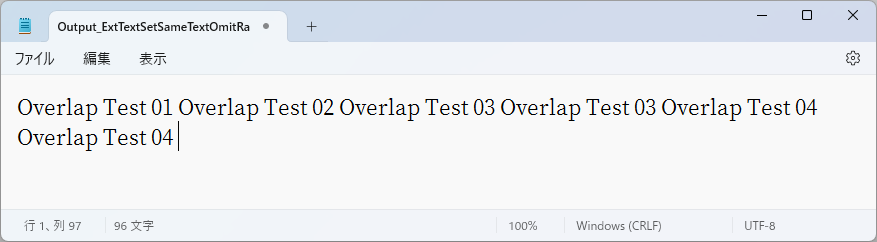
図9.16 操作例の出力テキスト(抜粋)
「Overlap 01」、「Overlap 02」は二重に読み取られず、1回だけ読み取られています。一方、重なり合ってはいるが遠い距離にある「Overlap 03」、「Overlap 04」は2回読み取られています。
入力PDFでいうと、図9.17の部分に該当します。

図9.17 入力PDFの拡大図。点線が今回除外された部分
比較としてテキストが重なった部分を除外せずに抽出した例も並べてみます。
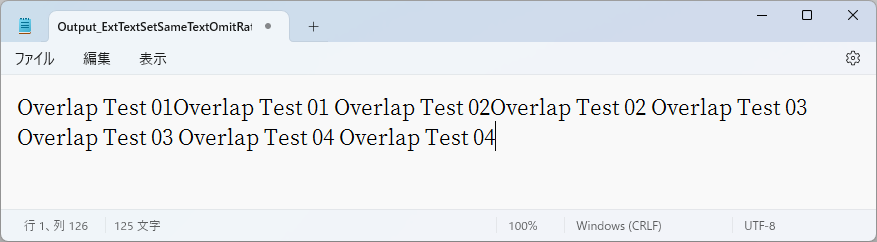
図9.18 テキストが重なった部分を除外しなかった場合の例(抜粋)