News Release
PDFからテキスト・表・画像データを抽出
『PDF Advanced Extractor V1.0』リリースのお知らせ
2023年2月28日

アンテナハウス株式会社(本社:東京、社長:小林徳滋、資本金:4,000万円)は、2023年2月28日より『PDF Advanced Extractor V1.0』を販売開始いたしました。
『PDF Advanced Extractor』は、PDFからテキスト・表・画像データを抽出し高度に利活用するためのソフトウェアです。
製品の操作画面でPDFファイルを1ページずつ確認しながら、テキスト(本文・表)の範囲、テキスト中で段落を区切る箇所、画像として出力する範囲、抽出順序などを指定し、プレーンテキストに保存できます。また、見出し・段落・表・画像を指定してHTML形式のテキストファイルに出力できます。
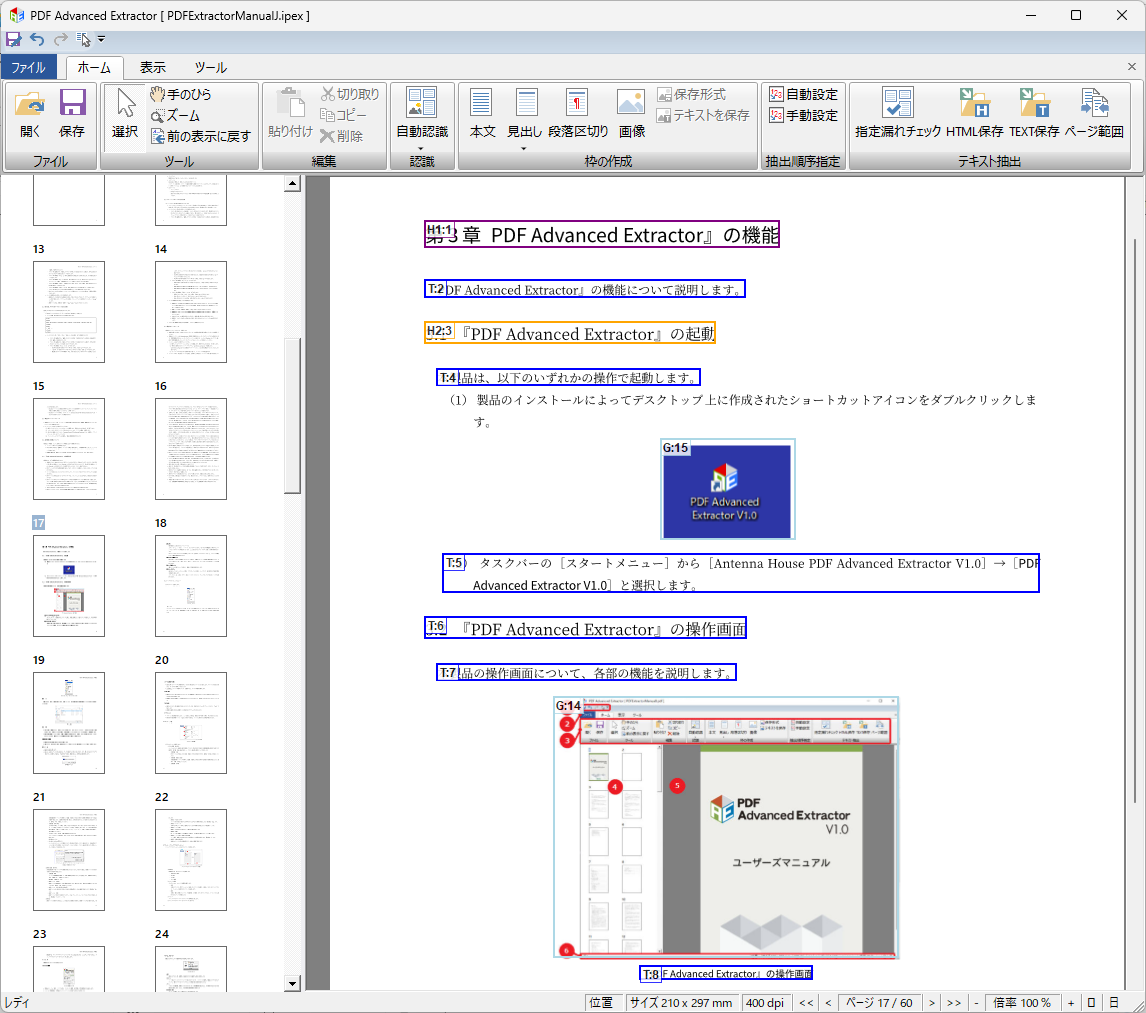
製品の主な特長
『PDF Advanced Extractor V1.0』は、PDFからのテキスト抽出を便利にする数々の機能をご提供します。
- 操作画面にPDFを表示して簡単な操作でテキスト・画像範囲を指定できます。
- テキストは本文・表・見出しの種類に分けて指定でき、それぞれにタグを付けたHTML形式のテキストファイルで保存できます。
- PDF内部のデータを高精度に解析し、テキスト・画像・表の各範囲、抽出順を自動で設定する機能を搭載しています。
- 抽出するテキストデータを画面上で直接編集して変更し、その結果をテキストファイルに保存できます。
- 通常のテキストデータに加えて、画像化された文字についてもOCR処理で文字コードを取得し、シームレスに抽出する機能を搭載しています。
- テキストの抽出順はマウス操作で簡単に変更できます。元データの文脈に沿った順序でテキスト抽出できるため、再利用の手間が軽減できます。
- 抽出順はテキスト・画像の両方に対して指定できます。これによりテキスト間の任意の位置に画像を挿入してHTMLタグ付きテキストファイルに出力するといった使い方ができます。
- 表の範囲には行数・列数の指定ができます。これによりHTMLタグ付きテキスト保存時に表(table)要素を付加できます。
- テキストの任意の箇所に段落区切りを挿入、同じ文字を重ねて太字にしている場合に重複文字を除外、ルビや注釈など不要なデータを抽出しない等、抽出処理を補完する便利機能を多数搭載しています。
- 画面上で指定した範囲のデータは本製品専用の情報ファイルに保存していつでも呼び出し、再利用できます。
- 画面上で指定した範囲のデータをテンプレートファイルに保存して別のPDFに適用できます。これにより、定型の帳票データなどレイアウトが共通で内容のみが異なるPDFからも簡単にテキストを抽出できます。
- PDFを自動認識して情報ファイルを生成する処理、テンプレートファイルを指定してテキストファイルに保存する処理は標準搭載のコマンドライン・インタフェースからも利用できます。これにより複数のPDFファイルに対し一括でバッチ処理を行うことができます。
動作環境
『PDF Advanced Extractor V1.0』は、Windows 64ビット版専用のソフトウェアです。Windows 32ビット版では利用できません。
| Windows x64版 |
Windows 11 Windows 10(64ビット版) |
|---|
ライセンスの種類と価格
| 種類 | 価格(税別) |
|---|---|
| シングルライセンス | 36,000円 |
| 既存/同一ユーザーの2本目以降の新規ライセンス | 27,000円 |
出荷開始
本製品の出荷開始は 2023年2月28日からです。
お問い合わせ先
〒103-0004
東京都中央区東日本橋2-1-6 東日本橋藤和ビル5F
アンテナハウス株式会社
- ◆ご購入に関するお問い合わせ(祝日を除く月~金曜日9:30~18:00)
- TEL : 03-5829-9030
FAX : 03-5829-9024
E-mail: sis@antenna.co.jp
URL : https://www.antenna.co.jp/