
コンピュータによるテキスト表記とPDFのフォント埋め込みについて
更新日: 2021/1/31
はじめに
PDFのフォント埋め込みとはなにか、フォント埋め込みがなぜ必要かについて理解することを主な目標とします。そのため必要な知識として、コンピュータでの文字の取り扱いに表記と情報処理の2種類があること、そして、文字コードとグリフ、アウトラインフォント、PDFのテキスト表示の仕組みとフォント埋め込みについて説明し、フォントを埋め込まない時に発生する問題などについても事例を挙げて解説します。
基礎知識
PDFへのフォント埋め込みについて理解するには、コンピュータの内部で文字を取り扱ったり、画面表示・紙に印刷する仕組みについての知識が必要です。そこで最初に前提となる知識についてできるだけ簡単に説明します。
字形、字体
一般の言語生活では、文字は言語を表記するための道具であり、主に書いたり・読んだりするために用いられます。これに対して、コンピュータで文字を扱うのは、一般の言語生活よりも多岐にわたっています。すなわち、電子メールあるいはコンピュータ間で通信したり、情報をデータベースに蓄積したり、検索したり、あるいは文書情報を解読、言語理解したりなど言語情報処理でも文字を扱います。
言語表記と言語情報処理とでは文字の取り扱いがかなり異なっています。PDFは印刷技術であるPostScriptから生まれてきただけに言語表記用としての文字の取り扱いのために様々な機能を持っています。フォントの埋め込みもその一種と言えます。
表外漢字字体表
表記用の文字についての規定の一例として、国語審議会(2001年、中央省庁の再編に伴い廃止。審議会の活動内容は実質的に文化審議会国語分科会が継承しています。)の「表外漢字字体表」があります。これは「印刷文字において標準とすべき字体である」印刷標準字体を定めるものです。
この文書では字体、書体、字形という用語を次のように定義しています。
字体 — 文字の骨組み。ある文字をある文字たらしめている点画の抽象的な構成のありかた。他の文字との弁別にかかわるものである。文字は抽象的な形態上の概念であるから、これを可視的に示そうとすれば、一定のスタイルをもつ具体的な文字として出現させる必要がある。
書体 — 文字の具体化に際して、視覚的な特徴となって現れる一定のスタイルの体系が書体である。例えば、書体のひとつである明朝体の場合は、縦画を太くして横画の終端部にウロコという三角形の装飾を付けたスタイルで統一されている。すなわち、現実の文字は、例外なく、骨組みとしての字体を具体的に出現させた書体として存在しているものである。
書体の例は、明朝体、ゴシック体、正楷書体、教科書体など。
字形 — 印刷文字、手書き文字を問わず、目に見える文字の形そのものを総称していう場合に用いる。
国語審議会は印刷分野を主な対象としているのですが、印刷文字は字形が一定のスタイルをもつ書体として準備されるということです。
字体の違いとデザインの違い
「表外漢字字体表」では、字体の違いとデザインの違いについても取り上げており、次のように説明しています。「デザイン差とは、活字設計上の表現の差」としています。文脈上、デザイン差と対比させる形で字体の違いという言葉を使っていますので、デザイン差の範囲での字形の相違は同じ字体と見なし、デザイン差に収まらないものは別の字体と考えていることになります。
デザイン差について、表外漢字字体表の付録に具体的な分類と例があります。
表外漢字における字体の違いとデザインの違い(国立国会図書館WARP Webアーカイブ:保存日:2019/12/4)※
「デザイン差があてはまっても字種を分ける場合は、デザイン差には該当しない。」という一文もありますので、デザイン差は字種の同じものの範囲で意味をもつとしています。
(1) 「しんにゅう/しめすへん/しょくへん」は、(a)![]() を用いるものと、(b)
を用いるものと、(b)![]() を用いるものがあります。これらは「3部首許容」とされています。印刷字体では標準は(a)だが、(b)を使っても良いということでしょう。特に「3部首許容」と言う表現を使っているのは、これらはデザイン差でなく、別の字体だが、標準として許すといういうことのようです。それにしても、この「3部首許容」という言葉の意図は理解し難いものです。
を用いるものがあります。これらは「3部首許容」とされています。印刷字体では標準は(a)だが、(b)を使っても良いということでしょう。特に「3部首許容」と言う表現を使っているのは、これらはデザイン差でなく、別の字体だが、標準として許すといういうことのようです。それにしても、この「3部首許容」という言葉の意図は理解し難いものです。
(2)「くさかんむり」については、明朝体では3画を標準としています。しかし、明朝体以外では4画も制限しないということなので、書体によって、デザイン差の許容範囲が違うことになります。このように表記の道具としての文字になりますと字形に対するこだわりが強くあります。
※2020年5月現在は、文化庁国語施策・日本語教育>国語施策情報>答申・建議・報告等>第22期 「現代社会における敬意表現」,「表外漢字字体表」及び「国際社会に対応する日本語の在り方」について(答申)>表外漢字字体表 参考Ⅲ より、
1 表外漢字における字体の違いとデザインの違いに該当します。「表外漢字における字体の違いとデザインの違い」の見方
文字コード
一方、コンピュータの内部で言語を取り扱うためには文字コードを使います。文字コードは言語表記よりもむしろ情報処理のための道具です。文字コードは大雑把には次のように定められます。
実際に使われている文字を収集します。その上で、字義が同じで字体が同一視できる文字は一つにまとめます。これを包摂する(Unification)と言います。こうして作成した文字集合の構成要素に一定の番号(コードポイント)を与えます。これを符号化文字集合と言います。なお、コンピュータで情報処理するときはコードポイントを一定の計算式でバイトのならびに変換して取り扱います。この変換方式を符号化方式と言います。
現在、符号化文字集合としてはUnicodeが最もよく使われています。Unicodeをコンピュータで使うときの符号化方式はUTF-8、UTF-16が一般的です。
日本では、符号化文字集合としてJIS規格も使われます。JISの文字規格は幾つかあり、それぞれが改訂の歴史をもちます。JIS X0213:2004が最新のJIS文字規格です。
JIS X0213でコードポイントがある文字の数は11,233です。この大部分はUnicodeにもコードポイントがありますが、次の図に示す文字はUnicodeにはコードポイントがなく二つのコードポイントの文字の結合文字で表さなければなりません。このように、異なる符号化文字集合の間では、コードポイントが必ずしも一対一の対応関係にならないことがあります。

漢字のコードポイント-字体-字形の3層モデルについて
符号化文字集合は上で述べましたように情報処理を目的とした抽象的なもので、表記道具としての文字とは抽象度のレベルが異なります。そこで文字コードと字体、字形がどのような関係になっているのかを考えて見ます。
JIS X0213では一つのコードポイントには包摂の範囲内で複数の字体が割り当てられています。字体をデザインして眼に見える形にした字形になりますと、さらに多様になります。この関係は次のような図で考えると分かりやすいと思います。
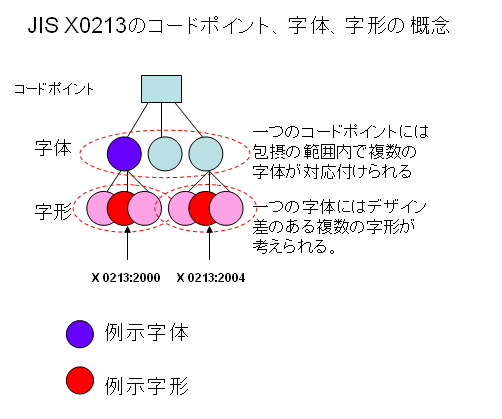
包摂の基準にはいろいろありますが、たとえば、国語審議会の「表外漢字字体表」で、3部首許容とした「しんにゅう、しめすへん、しょくへん」は、JIS X0213では、包摂される部分字体とされています。次の図をご覧ください。

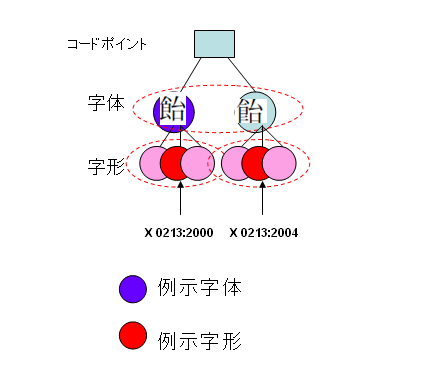
JIS X0213:2000とJIS X0213:2004での字体の変更
国語審議会が平成12年(2000年)に「表外漢字字体表」を答申したのを受けて、JIS X0213は、2004年改訂(JIS X0213:2004)で168文字のコードポイントの例示字体を変更し、さらに、10文字の追加を行った。例示字体の変更は、包摂の範囲内なので、コードポイントの規定の変更を行ったわけではないと考えられます。次の図を参照。
参考資料:JIS漢字コード表の改正について(PDF)(国立国会図書館WARP:経済産業省 保存日:2016/02/02-11/01)
フォントとグリフ
フォント技術やPDF Referenceでは、実際に表示される文字の形をグリフと言っています。グリフは国語審議会の用語で字形に相当します。コンピュータ組版の歴史は、まだ半世紀を経過していないと思いますが、文字とグリフの関係は、PostScriptが開発された当時は明確に区別されていませんでした。このため現在でもPDF Referenceなどで使っている言葉の用法に多少混同があるようです。
コンピュータで文字を表示する方法は幾つかありますが、次に、現在最も一般的なアウトライン・フォントについて説明してみます。
アウトライン・フォントとグリフ
アウトラインとはグリフの輪郭のことです。
アウトラインを記述する方法の中で、現在、最もポピュラーなのは、PostScript(Type1)フォントで使われている3次ベジエ曲線、およびTrueTypeフォントで使われている2次ベジエ曲線のふたつの方法です。
アウトライン・フォントでは、グリフの輪郭を多数の線分に分割し、各線分をベジエ曲線で表します。ベジエ曲線は、二つの端点とそれに加えて曲線の曲がり具合を制御する制御点のデータで表現することができます。従って、アウトライン・フォントのグリフデータの中核は、多数の線分の端点と制御点の集合ということになります。
グリフの可視化は次のステップで行われます。
- 可視化したいグリフのデータを取り出す。
- データを元にグリフのアウトラインを描く。
- アウトラインで表現したグリフの状態から、塗り潰すべき点を見つける。
- 塗り潰すべきを塗り潰す。
アウトライン・フォントをコンピュータのディスプレイに表示するには、全てのグリフについて、(1)~(4)のステップで点滅するドットのパターンに置き換えていきます。この処理を行うプログラムをフォントのラスタライザと言いWindowsのGDIやPostScriptを印刷するプリンタなど様々な機器にフォントのラスタライザが搭載されています。
アウトライン・フォントの良い点は、グリフをベジエ曲線という数学的な曲線で表していますので、拡大・縮小が自由にできるということです。
フォント・ファイル
一定のスタイルでデザインしたグリフを集め、そのメトリックス情報や文字特性など、文字を印刷用に組版(タイプセッティング)するための情報と共に一式まとめてファイルにしたものがフォント・ファイルです。フォント・ファイルにはそのフォントで表示できる全ての文字のグリフデータが収容されており、各グリフデータには識別番号(グリフID)がついています。
フォント・ファイルの形式には、幾つかありますが、最近は、OpenTypeフォントが主流となっています。そこで、以下ではOpenTypeについて取り上げます。
OpenTypeではグリフIDをCID(CFFアウトライン)またはGID(TrueTypeアウトライン)と言います。Unicode、JIS X0213などの文字コードは標準化されていますが、このグリフIDは標準化されたものではなく、フォント・ファイルの中で自由に決定されます。従ってフォント・ファイルと切り離して使うことはできません。
文字コードとグリフの関係
コンピュータ間で、通常、交換したり処理するデータは文字コードであってグリフデータではありません。文字コードとグリフIDへはどのように対応つけるのでしょうか。
フォント・ファイルの中には、文字コードからグリフIDへの対応表も含まれていますが、これをcmapと言います。
文字コードとグリフIDは一対一対応にはなりません。簡単な例では、日本語での表記法には、横書きと縦書きがありますが、記号類は横書きと縦書き用の2種類のグリフを持たせなければなりません。そして横書きと縦書きとでcmapを切り替える必要があります。
異体字
このほか、漢字には異体字があります。異体字はOpenTypeでは、フィーチャテーブルを使って、次の図のようにグリフIDを置換できます。
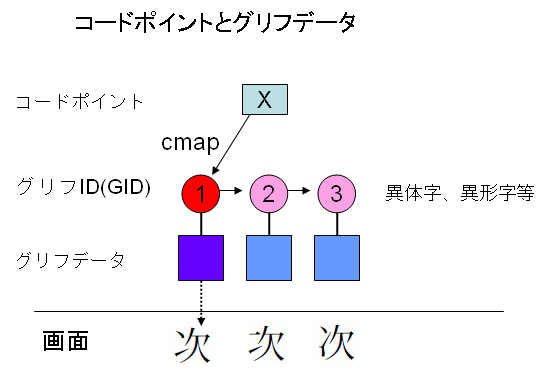
上の図は、文字コードXに対して、グリフIDは1番が通常対応するが、アプリケーションは、OpenTypeのフィーチャテーブルを使って、2番、3番に切り替えることもできることを示しています。パソコンのOSは、選択されたグリフIDに該当するグリフデータを使って、文字を画面上に可視化します。
上に述べた説明は日本語の場合ですが、多言語の表記では、文字コードとグリフの関係はより複雑になることがあります。
文字の位置によるグリフ切り替え
アラビア文字は、ひとつの文字に単独形、右接形、両接形、左接形の4つの字形があります。アラビア文字を表示するアプリケーションは、語中で文字が現れる位置によって該当するグリフを選択する必要があります。
リガチャ(合字)
ラテン文字、アラビア文字、デバナガリ文字などではリガチャといい、複数の文字が連続するとき、字形が個々の字形を並べたものとは別の字形に変わる場合があります。
PDFのテキスト表示の仕組み
PDFで文字を表示する基本について触れてみます。詳しい説明は、ISO 32000-1:2008 「9 Text」(pp.237-294)参考資料[1]を参照してください。
略図を示してみましょう。

この図で「文字列」と表した部分は表示したい文字となります。ラテン・アルファベットはABCのような文字のまま保存できます。CJK文字は文字コードの並びで表現するのが一般的ですが、フォントのグリフIDの並びで表すこともできます。
文字列には、使用するフォント・オブジェクト、文字の大きさ、文字を表示する位置など様々な情報が付随しています。
フォント・オブジェクトは、ページに付随する資源辞書の中のフォント辞書に詳しい情報が定義されています。フォント辞書は、Type1、 TrueType、CIDフォントなどのフォントの種類によって若干の差がありますが、フォントの種類やPostScript名、標準の幅、などを規定しているものです。
実際に文字を表示するためには、文字を表すグリフ・データ、フォントのメトリックスなどが必要ですが、これらの情報は、フォント・ファイルの中に含まれています。
フォント・ファイルは、コンピュータ上(Windows環境であれば、Windows/Fontsフォルダ内)にあったり、あるいは、アプリケーション独自のインストール・フォルダやアプリケーション内部あります。
フォントが埋め込まれていない場合の文字の表示
PDFにフォントが埋め込まれていない場合、PDFの中には、普通、文字コード(コードポイント)の並びがあり、その文字コードを表示するためのフォント・オブジェクトが指定されています。
- PDF中で指定されているフォント・オブジェクトとフォント辞書から、PDFを表示する環境であるPCに存在するフォント・ファミリーに対応付けする。同一のフォント・ファミリーが存在すれば問題ないが、存在しないと別のフォント・ファミリーの中で適切なものを決定する。
- フォント・ファミリーの中で、コードポイント⇒グリフIDに対応つける。
- 当該のグリフIDに対応するグリフデータを使って文字を可視化する。
PDFにフォントを埋め込まないときは、あるコードポイントの文字を可視化するのに、上のような過程を踏むことになりますので最終的に可視化される文字が、偶に、意図しない文字になることがありそうなことは想像が付くと思います。
PDFへのフォント埋め込みとは
PDFにフォントを埋め込むと、埋め込み処理の際に、コンピュータ上のフォント・ファイルから必要最小限の情報が取り出されて、PDF内部に取り込まれます。さらに、文字列オブジェクトは、原則として、文字コードではなくグリフIDの並びとなります。
略図で示すと次のようになります。
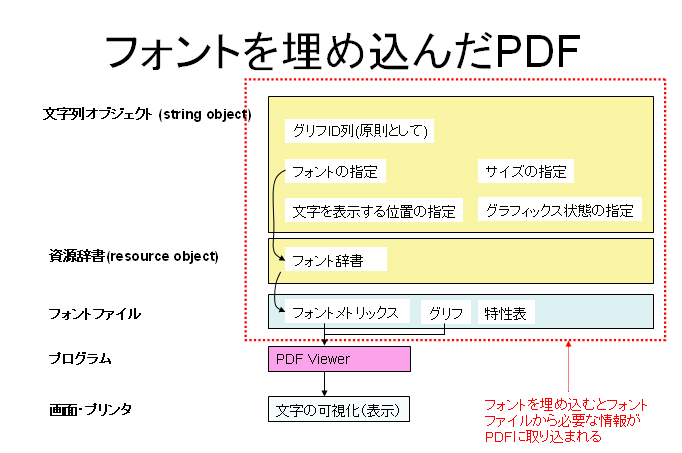
フォントを埋め込んでいないPDFでは、文字を表示するのに必要なフォント・ファイルがPDFの外側にありますが、フォントを埋め込むと必要最小限の情報がPDFに付随します。そこで、PDFを表示するViewerが埋め込んだフォントで文字を表示できるならば文字化けなどが発生することがなくなることになります。
フォントを埋め込まないPDFの表示の問題
フォントを埋め込まないPDFでは、通常、フォント資源はコンピュータ上の資源を使います。従って、PDFを作成した環境とPDFを表示する環境でフォントが異なる場合は、文字の字形が正しく表示されないことになります。この問題を避けるにはフォント埋め込みが有効です。次にフォントを埋め込みが有効になるいくつかの事例を紹介します。
Type 1フォントの廃止に伴うトラブルを避ける
アドビは2023年1月をもってType 1フォントのサポートを終了すると発表しています。サポート終了後は、Type 1フォントを使用して作成されたPDFに対してType 1フォントを使う編集はできなくなります。しかし、フォント埋め込んでいれば問題はありません。
Type1 データが埋め込まれたファイルはどうなりますか?
グラフィック要素として表示または印刷用に配置されている限り、EPS や PDF などのファイル形式に埋め込まれた Type 1 データに影響はありません。(参考資料[3])
MS明朝の字体変更によって発生する問題
Windows2000やXPにはMS明朝とMSゴシックVersion2.3が標準で添付されています。これに対して、Windows Vistaに標準で搭載されているMS明朝Version 5、MSゴシックVersion 5は、グリフIDが変更になり、JIS X0213:2004の例示字体変更を反映して一部の文字の標準グリフが変更になりました。
Windows Vistaの普及に伴って、Vista上でMS明朝、MSゴシックを指定して作成したPDFを、XPなどの環境で表示したり、あるいは、その逆にXPで作成したPDFをVistaで表示することが増えるでしょう。この時、MS明朝やMSゴシックで、字体変更になった文字は、フォントを埋め込まないと作成した環境と表示する環境で別の字体となります。
フォントを埋め込まない日本語PDFは英語版Windows上のAdobe Readerでは表示できない
WindowsXPのロケールが英語の状態で、英語版のAdobe Reader 7をインストールした直後の状態では、フォントを埋め込んでない日本語文字の入ったPDFはまったく表示できません。このことは、英語圏ではフォントを埋め込んでいない日本語PDFは内容を正しく表示できない、ということを示しています。
次の図は、「平成丸ゴシック」を指定した日本語文字を含む文書をPDFにして、Adobe Reader英語版で表示したものです。上がフォントを埋め込まない場合、下がフォントを埋め込んだ場合です。このケースでは、Windows環境に「平成丸ゴシック」フォントがインストールされているにも関わらずフォントを埋め込まない限り文字が表示されません。
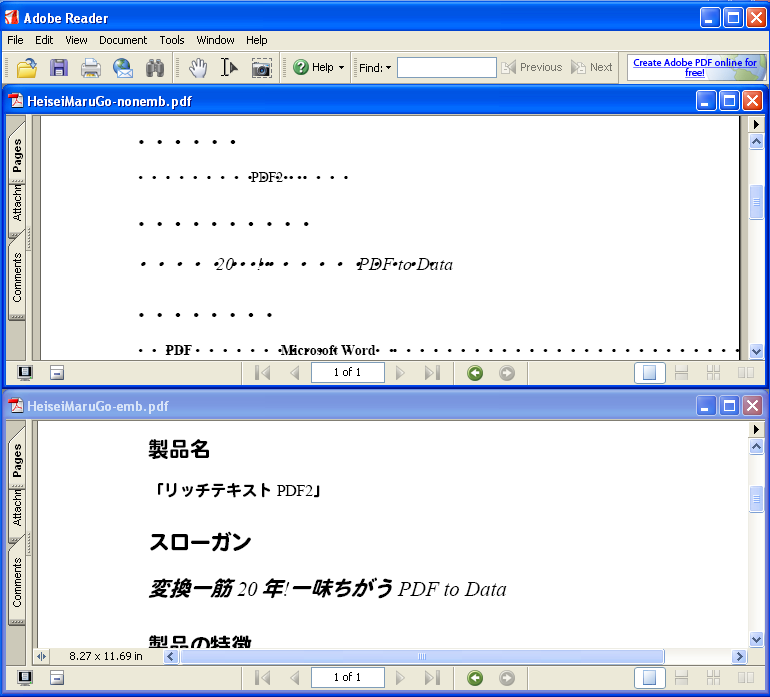
ここでひとつ気になりますのは、WindowsXPのロケールが英語の状態では、このままの状態から改善されないようだということです。
そこで、WindowsXPのロケールを日本語に切り替え、日本語フォントのファイルを表示すると、今度は次のように、Adobe Readerをアップデートします。アップデート後はフォントを埋め込んでないPDFファイルも正しく表示できるようになります。
Adobe Reader(英語版)は、MS明朝を指定した日本語文字については、Windowsシステムにフォントがあっても表示できないできません。では、日本語以外はどうなるか、を少し調べてみました。
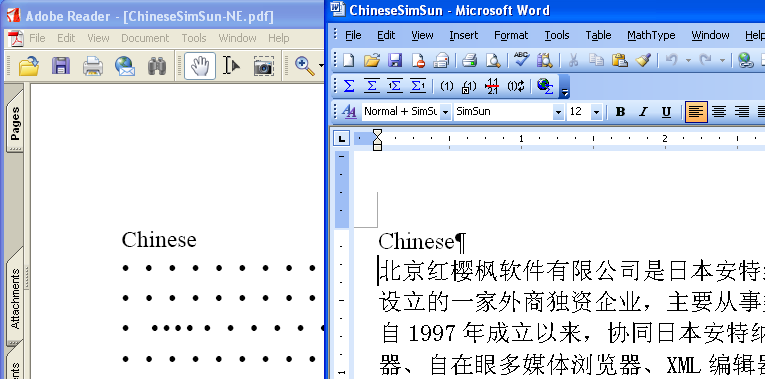
フォントを埋め込まない中国語PDFの表示
中国語簡体字にSimSunフォントを指定して、フォントを埋め込まずにPDFを作成してみました。右がWordのオリジナル画面、左が、フォントを埋め込まずに作成したPDFのAdobe Reader英語版で表示したもの。これを見ますと、中国語も同じように表示することができないことがわかります。
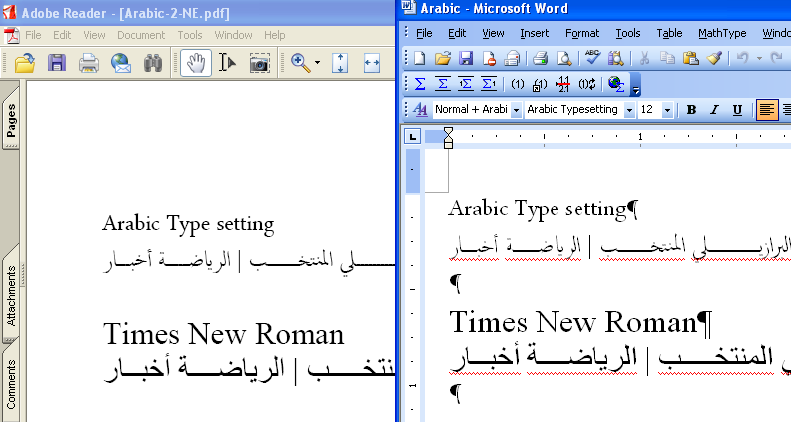
フォントを埋め込まないアラビア語PDFは作成できない
アラビア語(アラビア文字)の場合はどうなるでしょうか?試してみましたが、アラビア文字は、PDFを作成するときAcrobatにフォントを埋め込まないを指定してもフォントを強制的に埋め込んでしまいます。これはアラビア文字は、上述のように、文字が語内のどの位置にあるかで字形が変更になるため、フォントを埋め込まないとAdobe Readerでは正しく表示できないため、強制的に埋め込んでいるのだろうと思います。
■プロパティのフォント情報
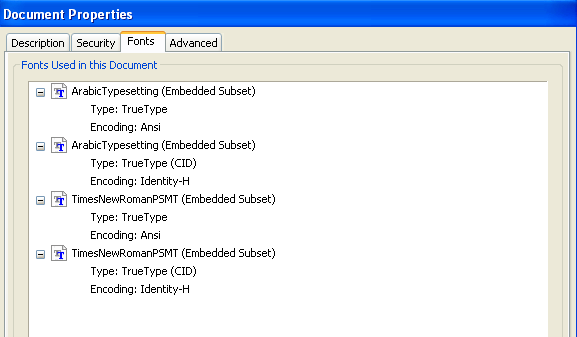
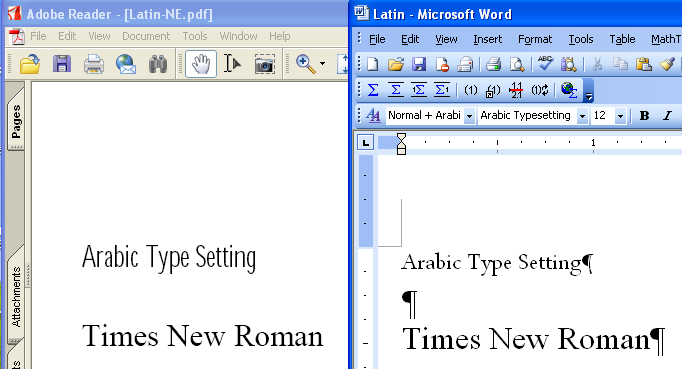
フォントを埋め込まないラテン文字PDF
前の例では、フォントを埋め込まないと指定しても、アラビア文字が入っていると、ラテン文字についてもフォントが埋め込まれてしまっています。そこで、ラテン文字だけならどうなるかを調べてみました。
■プロパティのフォント情報
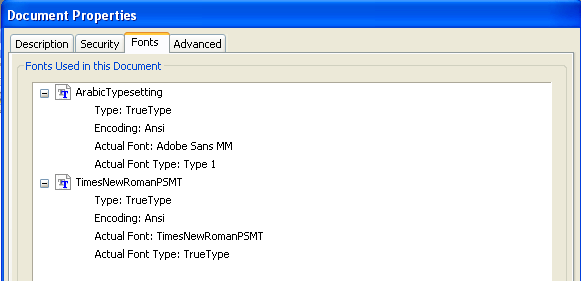
ラテン文字だけだと、フォントが埋め込まれない。Arabic Type Settingを指定した部分がAdobe Sans MM フォントに置換されて表示されていることがわかります。
このような結果を見ますと、Adobe Readerのフォントの選択では、Windows環境にどのようなフォントがあるかをチェックして適切なフォントを選択することを行っていないようです。
また、フォントを埋め込まずにPDFを作成すると、Arabic Type Settingのような特殊なメトリックスをもつフォントが、まったく異なるメトリックスのフォントに置き換えられています。
プロポーショナルフォントを使用した縦書き文書
Word 等でプロポーショナルフォントを使用した縦書き文書を Antenna House PDF Driver から PDF 出力し、Acrobat(Acrobat 8 Pro)で表示すると、次のキャプチャのように文字がきれいに揃いません(「MS P明朝」を使用しています。目立つ部分を赤い丸で囲ってあります)。
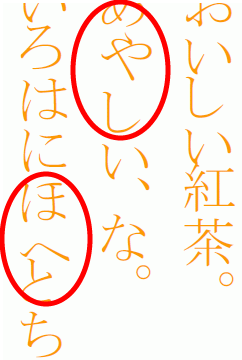
この問題ですが、どうやら Acrobat の表示の問題のようです。Acrobat 6 ではこの問題は発生せず元文書どおりに表示されますが、Acrobat 7 や 8 で表示すると上図のようになってしまいます。これは PDF Driver から出力した PDF に関わらず、Acrobat の Adobe PDF から作成した PDF でも再現してしまいます。
プロポーショナルフォントですので、縦書きに使用するべきではないのかもしれませんが、どうしても使用するのでしたら、フォントを埋め込めばとりあえずこの問題は回避できるようです。

フォント埋め込みとフォントの権利保護
フォント埋め込みに関連して、「フォント埋め込みは仮に部分埋め込みであっても著作権侵害にあたるのではないか」、という疑問を持たれる方が多いと思います。次に、この問題について検討します。
フォントの著作権
まず、前提としてフォントに著作権があるのかということですが、これについて判例もあります。
海賊版フォントに対する判決
プログラムとしてのフォントデータの著作権を対象
平成16年5月13日大阪地裁 平成15年(ワ)第2552号 著作権侵害に基づく差止等請求事件
モリサワ勝訴
出典:http://www.translan.com/jucc/precedent-2004-05-13b.html
私は法律の専門家ではありませんが、フォントの意匠・デザインに著作権がないと、万一の仮定をおきましても、アウトラインフォントはプログラムとデータから成り立っていますし、プログラムと同じように著作権で保護されてしかるべきと考えています。
ビットマップフォントについても、以前に「2006年10月17日 Google Docs/Spreadsheetsを初体験(4) — Kochi-Mincho」(アンテナハウスブログ PDF千夜一夜)で取り上げましたが、「東風明朝」の制作の元になったビットマップフォントが無断で複製されたものであったことが判明したしたことにより、「東風明朝」の制作・配布活動が中止になったという例もあります。
マイクロソフトは、Windowsに同梱しているフォントについて、次のページで著作権の取り扱いについて告知しています。
マイクロソフトの著作物の使用について - Microsoft
マイクロソフトは、フォントには著作権があると判断していると見られますが、日本語フォントの取り扱いについては「フォントの再頒布や、お客様のソフトウェアでの使用等の権利処理については」フォントベンダーに相談して欲しいと述べています。また、英文フォントについては各フォントの著作権者に相談して欲しいと述べています。
このようなことからフォントについては著作権法が適用されると考えるのが妥当と思います。
PDFへのフォント埋め込みは、明らかに、フォントのグリフデータ(アウトラインデータ)の複製と再頒布にあたります。従って、著作権者の許可なくフォントの埋め込みを行えば権利侵害と看做されることになるでしょう。
著作権者は節度のあるフォント埋め込みは認める傾向
では、PDFのフォント埋め込みでは、この問題をどのように解決しているのでしょうか?
まず、日本タイプグラフィ協会は、電子ドキュメントデータへのフォント埋込み機能に対するタイプフェイス/フォントの権利保護に関する声明書(平成10年11月20日)
を出しています。
出典: https://www.typography.or.jp/act/morals/moral4.html
これによりますと、概要は、次のような声明になります。
(1) ユーザの立場においては、フォントの埋め込みは非常に有効かつ利便性が高い技術革新と言えます。
(2) 配布されたPDFに埋め込まれたフォントセットのプロテクトを外して使用し、編集・校正することは、新たな文字組みを行うことになり、タイプフェイスの複製行為が行われることを意味します。
(3) 埋め込まれたフォントセットにより、タイプフェイスの複製・改変・二次的使用がより一層簡単となります。
従って、ユーザは、「埋め込んだフォントを用いて編集・校正などの新たな文字組を行う行為」、フォント埋め込みを不可としているタイプフェイス権利のフォントを埋め込まない、フォントが埋め込まれたPDFを配布するに際して、当該フォントの使用許諾契約書に従うこと、を求めています。
また、PDFへフォント埋め込み機能を有するプログラムの供給者に対しては、ユーザに対して禁止されている行為を助けるようなソフトウェアを開発しないことを求めています。
では、PDFへのフォント埋め込みの提唱元であるアドビはどうなっているのでしょうか?アドビは自社でも多数のフォントを制作して販売しています。
アドビのWebページには、フォントのライセンスについての情報が掲載されています。
Font Licensing Center
残念ながら日本語の解説は無いようです。
具体的には、こちらにライセンス契約書があります。
https://www.adobe.com/content/dam/acom/en/products/type/pdfs/eulas/eula-5seat-japanese-07.11.11.pdf
欧文フォント、和文フォントともフォント埋め込みに関する契約条項の文章は同じです。次のようになっています。
「お客様は、お客様の電子文書を印刷および閲覧するため、フォント・ソフトウェアのコピーをその文書に埋め込むことができます。埋め込むフォント・ソフトウェアがAdobeのウェブサイトhttp://www.adobe.com/type/browser/legal/additional_licenses.html で「編集可能な埋め込みのためのライセンス供与済」と指定されている場合は、さらに電子文書の編集の他の目的のためにもそのフォント・ソフトウェアのコピーを埋め込むことができます。」
なお、このページは現在、「追加ライセンス権限、フォント許可リスト」へ遷移します。
フォント埋め込み許可の分類
フォント埋め込みの許可には次の段階があります。
(1) 埋め込みを許可しない — アドビのフォントには埋め込みを許可しないフォントはありませんが、フォント・ベンダによっては許可していない場合もあります。
(2) 表示と印刷 — フォントをPDFに埋め込んで配布し、表示したり印刷に使うことができますが、PDFを編集するのに用いたり、他のPDFを作成したりするのに用いることができません。アドビのフォントはこの分類が多いようです。
(3) 編集可能 — 表示と印刷のほか、PDFの受け手がそのPDFの文書や構造を編集するに用いることができます。
(4) インストール可能 — 受け手がPDFに埋め込まれたフォントをPCにインストールして、新しいPDFを作成するのに用いることができます。これはPDFの受け手はフォントに関してオリジナルと同じ権利をもつことを意味しています。商業フォントではこの分類に属するフォントは少ないと思います。
フォントファイルの埋め込み許可フラグによる制御
さて、以上のようにフォントの埋め込みを許可したり、禁止したりするのは、フォントの権利者(ベンダ)の許諾事項となります。しかし、エンドユーザがフォントの使用許諾契約をチェックしたり、あるいは、権利者にいちいち確認するのは手間が掛かります。
これを自動的に行うために、TrueTypeやOpenTypeといった新しいフォントでは、フォントファイルのフォーマットの中に「埋め込み許可」に関する上記の(1)~(4)の分類情報がセットされるようになっています。
PDFを作成するソフトウエアは、この「埋め込み許可」の情報をチェックして、埋め込みするかどうかを判断することができます。
次の画面は、Antenna House PDF Driverの設定ダイヤログ「フォント」タブですが、Windowsにインストールされているフォントの一覧を表示するとき、埋め込みが禁止されているかどうかをチェックして鍵のマークで表示するようにしています。
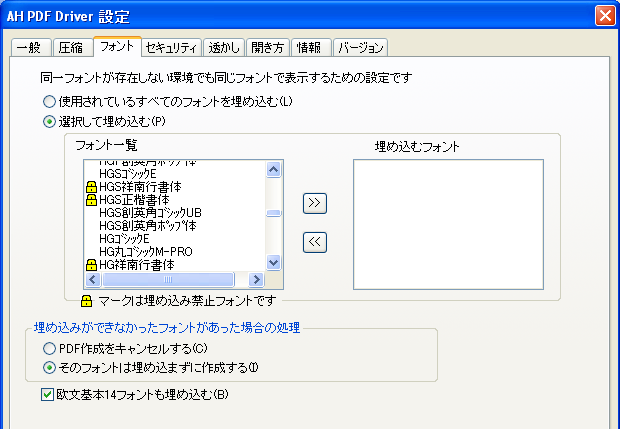
比較的新しいフォントであれば、このようにプログラムで埋め込み許可状態をチェックできます。しかし、Type1のような古いフォントでは、こうしたフラグはありませんので、権利者が許可しているかどうかを個別に確認する必要があります。
フォント埋め込みについてのQ&A
<質問>
PDFへの出力におきまして「帳票の印字をMS明朝の太字で統一したい」という要求がありますが、私の認識では「対応するためには、市販のフォントを購入し、PDFの表示を行なうPC上にインストールする必要がある」と考えていますが、何か対応策は、あるのでしょうか?
<回答>
PDF作成時にフォントを埋め込むことで、PDFを表示する環境にフォントは不要となります。
但し、前提条件があります。
(1)PDF作成ソフトが、フォント埋め込み機能を実装していること。
(2)PDF表示ソフトが、埋め込んだフォントを使って表示する機能を実装していること。
<質問>
フォント埋め込みをおこなった場合は、対象フォント全体がPDFファイルに埋め込まれることになり、ファイルサイズがかなり大きくなりますか?そのPDFで使用しているフォントだけが埋め込まれるということでは無いですね?
<回答>
フォント埋め込みは、ソフトによって実装方法は違うと思いますが、アンテナハウス製品の場合は、欧文フォントは文書の中で使用しているフォントの全文字を埋め込みます。
和文フォントの場合は、文書中で使用しているフォントの中で、さらに使用している文字のグリフアウトラインデータのみをPDFに埋め込みます。(サブセット埋め込み)
従いまして、PDFファイルは、それほど大きくはなりません。なお、他社の製品でフォントをどのように埋め込んでいるかは、その会社にご確認いただく必要があります。
お断り
本記事の内容は、主に2006年の「PDF千夜一夜」を整理したものです。このため参照している仕様などに改訂されているものがありますが、本記事では古いままになっている箇所があります。この文書の記述内容はできるだけ正確を期していますが、一部に理解の誤りが含まれる可能性があります。アンテナハウスはここに書かれた内容の正確性を保証するものではありません。また、当社プログラムの実装とも特に言及した箇所を除いて関係していません。
関連情報
お問い合わせは
本ページへのご意見・ご質問は、info@antenna.co.jpまでお気軽にお問合せください。
また、弊社オンラインショップでは本ページで紹介した製品をお得な価格でご購入いただけます。是非ご利用ください。