紙の情報をコンピューターに取り込むOCR
更新日:2020-02-13
オフィスの古い文書、スキャナで取り込んだだけで満足していませんか? いざその資料を見ようとするときに、ファイル名から探して苦労して見つけた後、今度はそのファイルを頭から読んで必要な箇所を探して……。これでは紙で管理していた時代と大きな違いを感じることは難しいのではないでしょうか。
紙をデジタル画像にするだけでは、毎回人間が資料とにらめっこをすることに変わりありません。 画像の中の文字をコンピュータが処理できるように変換してやることで、業務の自動化・効率化を図ることができます。
このページでは、画像をコンピュータで扱える情報として取り込むためのOCR技術の概要と、OCR製品を活用するために役立つ知識を紹介します。
用語説明
OCR
OCRとは、Optical Character Recognitionという英語の略で、日本語では光学的文字認識と訳されます。
- 紙に印刷された文字をイメージスキャナやデジタルカメラなどで読み取り、
- 画像化された情報から文字情報を識別し、
- コンピュータで処理可能な情報(文字コード)を抽出する技術またはその装置
を指します。装置あるいはソフトウェアを指す場合、OCRは「Optical Character Reader」の略称としても使われます。
透明テキスト付きPDF
通常、スキャナで取り込んだ書類やスクリーンショットの画像から作成されたPDFにはテキストデータはついていません。 こういったPDFでは、文字がある部分を選択して「コピー」などの操作ができません。
OCRによって得た文字情報を、画像として作成されたPDFに透明なテキストデータとして埋め込んだPDFを「透明テキスト付きPDF」と呼びます。
活字OCRの歴史
世界では文字認識技術開発は1900年前後から本格的に始まり、活字を読み取るOCR製品は1950年ごろに登場したようです。
1978年の汎用OCR製品、FACOM6312B(富士通製)が制御機能にマイクロプロセッサを採用し、OCR機能ソフトウェアの先駆けとなる、と[1]に紹介されています。
国内での次の大きな進展は、1988年のFACOM6365(富士通製)です。この製品では、読み取り対象の位置が決まっていた「帳票OCR」であった従来の日本語活字OCRから、新聞や印刷書類といった媒体からの読み取りに対応しました。汎用的な文書のOCRが可能になったのです。
その後Windows OSを搭載したグラフィカルなPCやスキャナ製品が普及すると、OCR機能をソフトウェアとして製品化したものが販売されるようになっていきました。
近年の動きとしては、AR技術や機械翻訳とあわせ、カメラで映した外国語のリアルタイム翻訳の試みなど、OCR単体ではなく他の技術と組み合わせた発展が行われています[2]。
OCRの概略
画像で取り込み
スキャナでスキャンした紙の原稿は画像データとしてパソコンに取り込まれます。画像データの種類はお使いのスキャナの仕様によって異なりますが、最近はPDF形式が使用されることが多いようです。PDFであっても内部には画像データのみ格納されています。
領域の認識
取り込んだ画像には、当然のことながら紙の原稿のレイアウトが写されています。画像 1のように、人間が原稿を見て「ここからここまでの部分は文章」「この部分は図形」「これは画像」と範囲を認識するように、OCRも各部分を認識します。これを領域(レイアウト)認識または領域解析と呼びます。
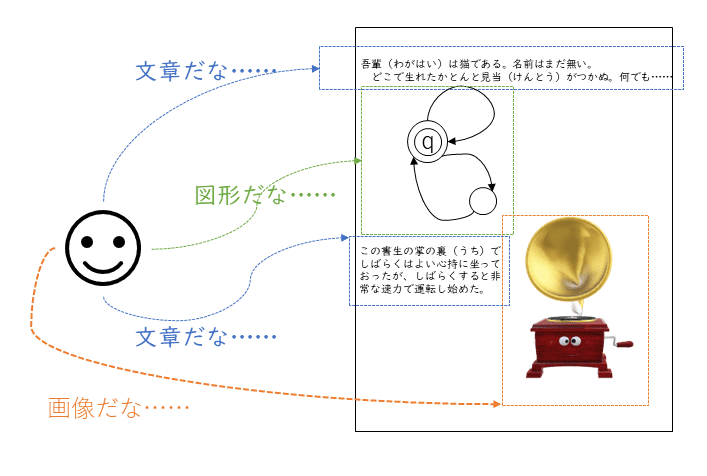
文字の認識
上記で文字領域と識別された部分について文字データの読み込み(抽出)を行います。ただし、人間が文字を読み取るのと比較して、コンピュータが文字を読むことは簡単なことではありません。人間の脳は、乱暴に書かれた手書き文字やかすれた文字などを読む場合、曖昧な部分を的確に補って正しく認識する能力を備えていますが、コンピュータはこうした認識が大の苦手です。例えば、画像 2は元の文字画像が鮮明でないために、文字の誤認識が出てしまう例です。
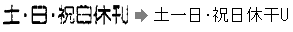
このため、さまざまな方法が考案されて文字の認識率を高める努力がされていますが、文字の認識率が100%(つまり完全)ということにはなかなかなりません。文字のかすれやつぶれがないなどコンディションの良い活字を認識した場合、一般に98%くらいの認識率であれば正確といえるようです。
認識結果の保存
OCR処理された結果はそのままでは利用することができません。認識された文字や画像などの情報をパソコン・ユーザーが扱える形式、たとえばWordやExcelなどのOffice文書やテキストファイル、透明テキスト付きPDFなどに保存することで、文字の検索に利用したり、編集して別の文書に再生したりといったことが可能になります。
OCRの使いどころ
文字のかすれやつぶれなどがあって品質が低かったり、文字と文字の間隔が狭い場合などは、どうしても認識率が低下してしまいます。 また、広告などで使われる装飾された文字や背景に模様がある文字、イタリックのように斜めに寝てデザインされた文字などはやはり苦手なものです。
では、OCRはまったく使えないかというと、決してそうではありません。例えば、画像 3はA4サイズの原稿を弊社の「瞬簡PDF 変換」のOCR機能を使用してWordに変換した例です。この原稿に含まれる文字数は約1600字あります。
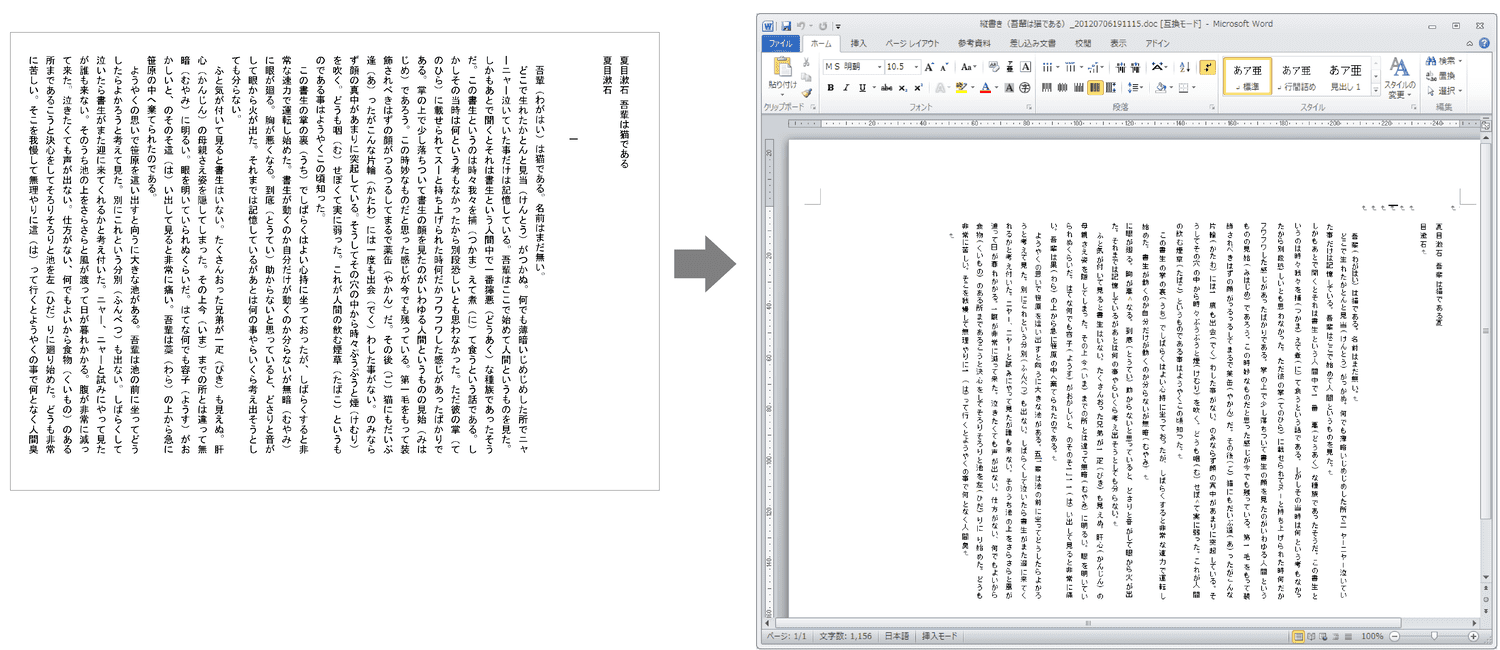
これを、もしOCR技術を使わないで取り込むとしたら、他の手段としてはキーボードから直接文字を打ち込むことくらいかと思います。原稿が1枚きりであればそれも選択肢として考えられます。しかし10枚、20枚となると、負担は大きなものになります。
紙の状態のままではそもそも検索できないことを考えると、仮に誤認識が発生してしまうとしても、十分実用できるのではないでしょうか?
OCRの併用
手書きの書類をコンピュータに入力する代行サービスは昔から存在していました。近年の新規事項としては、代行作業者が海の向こうでもスピーディに作業できる仕組みが整えられることや、手軽に携帯端末のカメラなどで撮影した画像を代行作業者へ送信したり、別のアプリサービスに結果を保存してもらったりできることでしょうか。
こういった代行サービスでも、OCRを活用している現場があるかもしれません。人間には機械処理ほど大量の処理はできません。まずOCRを使って作業量を減らし、人間が誤認識を訂正する、といった仕組みによって「OCRによる文字認識率の限界」「人間が可能な作業量の限界」双方を解決することが可能になるのです。もちろん、人手を介するために利用状況によってはOCR単体のサービスよりも時間がかかってしまうこともあるでしょう。
OCRでの誤認識の原因
OCRの精度があまり良くない場合、以下の原因による場合があります。
- 紙の原稿にかすれや汚れがある場合
- 文字の上に網掛けや線が重なったり、文字と文字の間隔が狭い場合
- 文字に傾きや装飾があったり、文字の字体が特殊である場合
- スキャナで読み取る際に文字の解像度が低かったり、歪みがある場合
- OCR処理で文字領域、画像領域などのレイアウトを正しく判別できない場合
OCRをかける画像の解像度
OCRで使う解像度はスキャナなどで取り込む画像の品質を表すもので、dpi(ディーピーアイ)という単位を使います。これは、1インチ(2.54cm)の間隔にどれだけ物理的な点(画素)が配置されているかを示すもので、同じ大きさの画像で比べた場合は、解像度の値が大きいほど高精細な画像が得られます。以下はそれを模式図にしたものですが、画像 4にあるように解像度が小さいと曲線などで滑らかな表現ができなくなります。
一般にOCR処理では、300~400dpiの範囲が適切なOCR結果を得る解像度だと言われています。それ以上解像度を上げてもファイルサイズが大きくなるばかりで、OCRの変換精度はあまり変わらないか、逆に悪くなってしまう場合もあります。
実際に異なる解像度でスキャナから取り込んで比較してみましょう。画像 5は、スキャナの設定でそれぞれ 200dpi/400dpi に解像度を変更してJPEG形式に保存したデータの一部を示しています。

ちょっと分かりづらいかも知れませんが、ブラウザの表示倍率をあげて見ていただくと両者の違いが分かります。以下は、この二つの画像を弊社のOCR変換製品でテキストファイルに変換した結果です。

解像度が200dpiだと文字化けしてしまう箇所が、400dpiでは(完全ではないですが)おおむね正しく認識できていることが確認できます。
そうすると、もっと解像度を高くしてスキャンすれば更に良い結果が出せそうに思えます。ところが、必ずしも解像度を上げれば結果が良くなるというものでもありません。画像 6は、スキャナの設定を600dpiにして変換を行った結果です。

解像度を上げても、あまり変換結果に影響がないことが確認できるかと思います。今回使用したJPEGデータの場合、400dpiのときのファイルサイズは約1.4MBですが、600dpiでは約2.7MBでした。
OCR処理を使って文字の取り出しを行う際には、スキャンの段階から適切な解像度を設定していただくことでより良い結果が得られます。 ご参考にしていただければ幸いです。
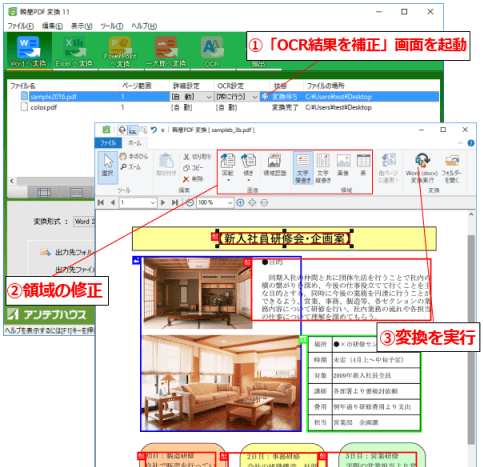
『瞬簡PDF 変換』でのOCR補正機能
- OCR処理で文字領域、画像領域などのレイアウトを正しく判別できない場合
『瞬簡PDF 変換』ではOCR処理時に文字領域、画像領域などのレイアウトを正しく判別できない場合、領域の大きさ・種別・位置などを手動で変更したり、画像の傾き・回転などの補正を行うことで、画像PDFの文書ファイルへの変換時のレイアウト保持をより正確に行うことができます。OCR補正機能は画像 7のように利用します。