自動認識
表示しているページからテキストデータや画像データの範囲を認識し、対応する枠を自動で作成・表示します。
図3・29 自動認識
ページを解析して認識
- ボタンをクリックすると、表示しているページについてPDF 内のデータを解析し、テキスト枠(「本文」/「表」)・画像枠を自動で作成します。
【ヒント】
- この処理では、ページ内で抽出可能なテキストのみを識別してテキスト枠を作成しますが、枠の範囲は内部のデータ配置に依存するためテキスト枠が複数に細分化して作成される場合があります。複数に分かれたテキスト枠は、Ctrlキーを押しながらマウスで順に選択し、右クリックメニューから「結合」をクリックすることで1つの枠にまとめることができます。
- ページの自動認識によって作成されるテキスト枠の種類は、「本文」または「表」のいずれかです。
- 段組が設定されたページを解析する場合は、オプション[段組みの設定]であらかじめ段組の向きと段数を指定しておくと、より正確にテキスト枠が認識されて枠の抽出順を自動付番できます。
範囲を指定して認識
ボタンをクリックすると、自動認識を行うページを指定するダイアログボックスを表示します。
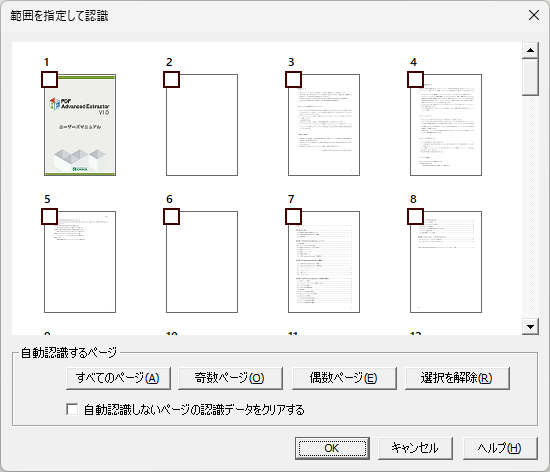
図3・30 「範囲を指定して認識」ダイアログボックス
- 自動認識したいページを以下のいずれかで選択します。
- すべてのページ:すべてのページを対象に、自動認識処理を行います。ページ数や内容によっては処理に時間がかかる場合があります。
- 奇数ページ:奇数ページを対象に、自動認識処理を行います。
- 偶数ページ:偶数ページを対象に、自動認識処理を行います。
- 選択を解除:選択したページのチェックをすべて解除します。
【注意】
- 対象ページに既存の認識情報がある場合は、新しい情報で無条件に上書きされます。問い合わせは表示されません。
【ヒント】
- 任意のページを選択したり解除する場合は、ページのサムネイル画像の左上にある"□"をクリックすることで、チェックを変更できます。
- 「自動認識しないページの認識データをクリアする」をチェックすると、選択対象外のページにある既存の認識情報を初期化(クリア)します。
ページを何も選択しない状態で、このチェックだけオンにすると、すべてのページの認識データをクリアできます。