『PDF Advanced Extractor』では、表示された画面上でテキスト抽出を行いたい箇所をテキスト枠で囲むことによりテキストデータの抽出範囲と抽出順を指定します。
また、テキスト抽出時に画像ファイルとして保存したい範囲を画像枠として任意に指定します。これにより、ページ上の表やグラフなどの領域を1つの画像にまとめて保存し、HTMLファイルからリンクして表示するような利用が可能となります。
PDFファイルの指定
- PDFファイルを指定すると、操作画面上に1ページ目の内容を表示します。
図4・2 PDFファイルとサムネイルの表示
テキスト枠の作成
- テキスト枠は、以下のいずれかの方法で作成します。
- (1)リボンの[ホーム]タブから[認識]グループにある[自動認識]ボタンをクリックし、表示されたプルダウンメニューで[ページを解析して認識]を選択します。
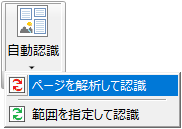
図4・3 [ページを解析して認識]を選択
- ページ上に既にテキスト枠や画像枠が存在する場合は、事前に警告ダイアログボックスを表示して削除の確認を行います。
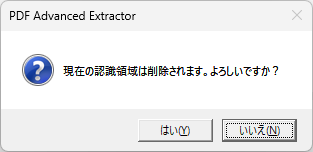
図4・4 枠を削除する場合の確認ダイアログボックス
- 任意のページ範囲や、全ページを対象に自動認識を行いたい場合は、表示されたプルダウンメニューで[範囲を指定して認識]を選択します。ページ指定を行うダイアログボックスを表示し、選択したページについて一括で自動認識処理を行います。
図4・5 「範囲を指定して認識」ダイアログボックス
- 表示されたダイアログボックスで、以下の操作を行います。
- ページのサムネイル
サムネイル画像の左上にあるボックスをクリックして、自動認識するページを個別に指定します。 - 自動認識するページ
自動認識するページを、以下のいずれかのボタンで指定します。- すべてのページ:PDFの全ページを対象に認識します。
- 奇数ページ:指定済みの選択を解除し、奇数ページのみ認識します。
- 偶数ページ:指定済みの選択を解除し、偶数ページのみ認識します。
- 選択を解除:指定済みの選択をすべて解除します。
- 自動認識しないページの認識データをクリアする:既に認識結果があり、自動認識対象外となるページについて既存の認識結果を削除します。
- (2) リボンの[ホーム]タブから[枠の作成]グループにある[本文]ボタンをクリックし、マウスで画面上のテキストを囲む任意の範囲をドラッグします。
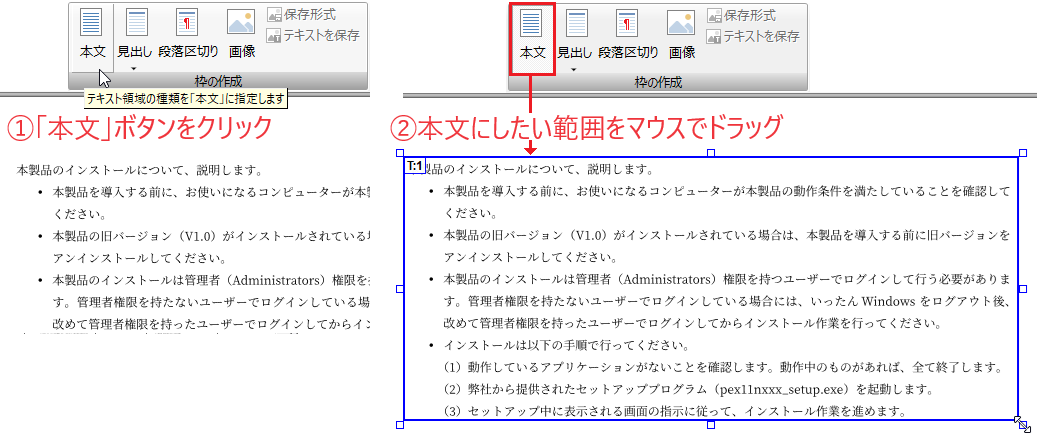
図4・6 本文枠を新規に作成
- 任意のテキストをHTMLの見出しタグで出力したい場合は、[見出し]ボタンをクリックして表示されるプルダウンメニューから見出しのレベル(1~6)を選択後、マウスで枠の範囲をドラッグします。
- [本文]または[見出し]ボタンをもう一度クリックすると、テキスト枠の追加を解除します。
【注意】
- テキスト枠は画面上の任意の位置に作成可能です。この場合、同一のテキストデータに複数のテキスト枠を重ねて指定するとテキスト抽出時に同じ文字が重複して出力されますので、ご注意ください(初期設定ではテキスト抽出実行時に警告ダイアログボックスを表示します)。
画像枠の作成
- 画像枠は、以下の手順で作成します。
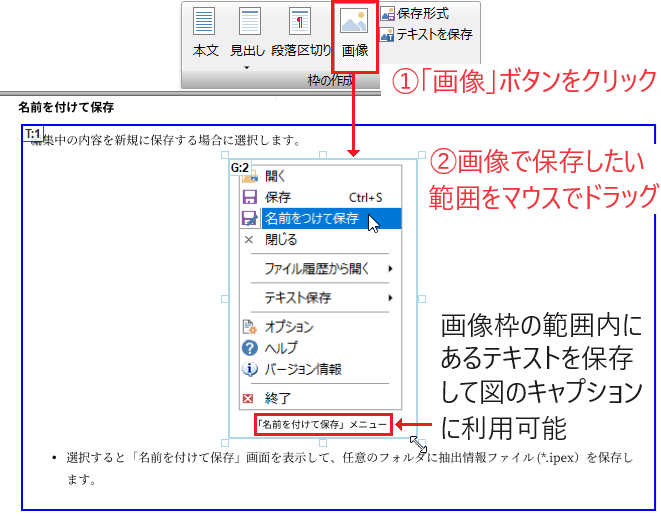
図4・7 画像枠を新規に作成
- (1)[枠の作成]グループから[画像]ボタンをクリックします。
- (2) 画面上にマウスを移動し、画像として保存したい範囲をマウスでドラッグして画像枠を作成します。
- (3) 画像枠が選択状態にあるとき、[保存形式]ボタンをクリックして画像ファイルの形式(PNG/JPEG/SVG)を指定します。
- (4) 画像枠の範囲内にテキストデータが含まれる場合は、[テキストを保存]ボタンをクリックするとテキストデータを画像と一緒に保存できます(図の赤枠の箇所)。
- (5)[画像]ボタンをもう一度クリックすると、画像枠の追加を解除します。
- 画像枠を設定してプレーンテキストまたはHTMLタグ付きテキストで保存を行うと、抽出された画像の情報を一覧(サマリ)にして出力先のサブフォルダにCSVファイルで保存します。
画像サマリは抽出された画像の管理などに利用できます。

図4・8 画像の情報をサマリに保存