OCRオプションの設定
OCRオプション設定
内部に文字データを含まないPDF / 画像ファイルから文字を認識するにはOCR(文字認識)処理が必要です。OCR処理は既定値で最良の性能が発揮できるように調整されていますが、元の画像の状態によっては条件を変えることでより良い結果が得られる場合があります。
以下では、OCR条件(OCRオプション)の設定方法について説明します。
OCRオプションの設定方法
OCRオプションの設定を変更するには、以下の2通りの方法があります。
① 変換処理全体でOCRオプションを設定する

図3・57 「OCR条件の既定値」から[設定...]をクリック
- 「リボン」を「ファイル」タブに切り替えます。
- 「オプション」⇒[一般]⇒「OCR条件の既定値」を選択します。
- [設定(S)...]をクリックして表示される、「OCR設定」ダイアログボックスでOCR条件を設定します。ここで設定した内容は、ファイルリストビューに登録されたすべてのファイルのOCR設定条件に初期値として適用されます。
② ファイル個別にOCRオプションを設定する
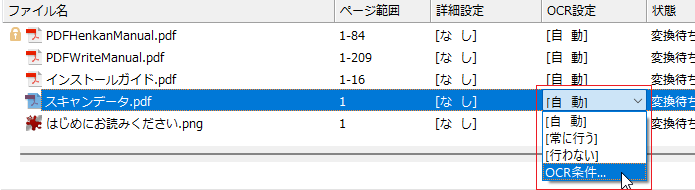
図3・58 プルダウンメニューから「OCR条件...」を選択
- ファイルリストビューで任意のファイルを選択し、OCR設定欄をクリックします。
- プルダウンメニューから「OCR条件...」を選択して「OCR設定」ダイアログボックスを表示します。ここで設定した内容はファイル個別の設定として、変換処理全体で指定されたOCR設定条件に優先して適用されます。
- OCR設定条件を既定値から変更した場合は、プルダウンに「*変更あり」と表示します。
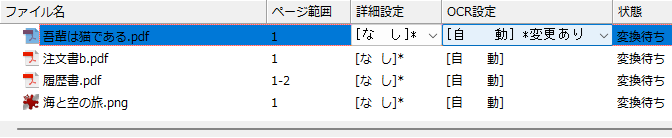
図3・59 「OCR条件...」を変更
 【ヒント】
【ヒント】
例えば一括でOCR処理したいPDFが複数ファイルあるとします。そのうち1ファイルが英語で作成され、それ以外はすべて日本語で作成されたPDFファイルだったとします。この場合、以下の手順を実行することですべてのファイルに適切なOCR処理を行えます。
- 一括処理したいPDFファイルをリストビューに登録する前に[OCR条件の既定値]で「OCR設定」ダイアログボックスを表示します。
- 言語に[日本語]を指定して[OK]をクリックします。
- 次に処理したいファイルをすべてリストビューにドラッグ&ドロップします。
- 一覧から英語のPDFファイルを選択し、OCR設定欄をクリックして「OCR条件...」を選択し「OCR設定」ダイアログボックスを表示します。言語を[英語]に変更して[OK]をクリックします。
- 変換を実行します。
- それぞれのPDFファイルが指定された言語でOCR処理され、文字認識の結果が変換先に反映されます。