5–4 OCR処理を使った変換・その他
-
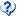 イメージスキャナーを使って取り込んだデータをOCR処理して変換すると、処理エラーが発生する場合があります。
イメージスキャナーを使って取り込んだデータをOCR処理して変換すると、処理エラーが発生する場合があります。
-
 本製品を使って画像データから変換する場合、いったんページ全体を画像に変換し、これを対象としてOCR処理します。この場合、画像解像度(dpi)の値を高く指定しているとメモリーを多量に消費するために画像化に失敗することがあります。
本製品を使って画像データから変換する場合、いったんページ全体を画像に変換し、これを対象としてOCR処理します。この場合、画像解像度(dpi)の値を高く指定しているとメモリーを多量に消費するために画像化に失敗することがあります。
このようなときには、スキャナーの設定で解像度の値を小さく設定して取り込んだ後、変換してみてください。ただし、この値を低くし過ぎると認識率が低下します。スキャン対象となった画像にもよりますが、一般的に300~400dpiの範囲で指定するのが適当です。
- イメージスキャナーを使って取り込んだデータをOCR処理して変換すると、文字化けがひどく期待した結果が得られません。
- 本製品で文字が画像化されたPDFファイルから変換する場合、いったんPDFファイルのページ全体を画像に変換してからOCR 処理します。
この場合、元のPDFファイルの状態により画像化された文字認識率が左右されます。
スキャンされたPDFファイルの画像の品質が元々低い場合には、OCR処理によって文字を認識することが困難です。状態にもよりますが、おおよそ200dpiを境にこれ以下の解像度の場合、文字認識がかなり低下します。
そうでない場合には、[OCR設定]ボタンをクリックして表示されるダイアログの[DPI値]で、高解像度に設定することで改善する場合があります。ただし、解像度を高くすると処理にメモリーや処理時間を大量に必要としますので、注意してください。
- [スキャナーから追加する]を選択するとエラーが表示されて次に進めません。
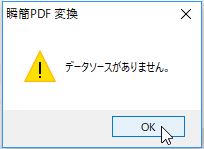
- [スキャナーから追加する]を選択したときに以下のエラーが表示された場合は、お使いのパソコンにスキャナードライバーがインストールされていない可能性があります。
スキャナーのCDまたはメーカーの製品ページから機種とOSに適合したスキャナードライバーを取得し、インストールしてください(スキャナードライバーの詳細は、各スキャナーメーカーにお問い合わせください)。
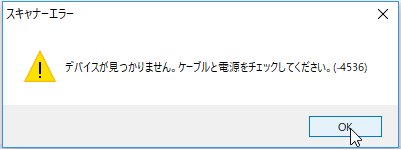
- 「ソースの選択」画面でスキャナーを選択するとエラーが表示されて次に進めません。
- 「ソースの選択」画面でスキャナーを選択したときに以下のエラーが表示された場合は、スキャナーがパソコンに接続されていない可能性があります。その場合は、いったんエラー画面を閉じ、スキャナーがお使いのパソコンに接続されているかを確認してから、再度[スキャナーから追加する]の操作を行ってみてください。
- OCR処理によって出力されるPDFファイルのサイズが、処理対象となるファイルより大きくなります。
- 処理対象となるのが画像ファイルの場合、ファイルのフォーマットによっては、処理対象となる画像ファイルより出力されるPDFファイルのほうが、ファイルサイズが大きくなる場合があります。(特にJPEGファイルの場合)
処理対象がPDFファイルの場合、ページをいったん画像に変換してOCR処理し、得られたテキストと変換した画像とでページを再構成してPDFファイルに出力します。
そのため、PDFファイルの内容やOCR処理オプションのDPIの設定によっては、出力されるPDFファイルのほうがファイルサイズが大きくなる場合があります。一般にDPIの設定値が大きいほど、出力されるPDFファイルのサイズが大きくなります。
 【ヒント】
【ヒント】
- [OCR結果をPDFファイルに埋め込む]処理を選択した場合、変換設定で[元データの情報を保持してOCR結果を埋め込む]を選択すると、既定の変換に比較して作成されるPDFファイルのサイズを小さくできる場合があります。
- OCR補正機能を使って表の領域を指定したところ、領域の中の文字が何も変換されません。
- OCR補正機能を使って表の領域を指定した場合は、領域中に含まれる線の情報を参照して表とその中に含まれるテキストを認識します。このため、表領域を指定した範囲の中に線の情報が何もない場合は、表として判断がされず、テキストを含めて変換対象となりません。線の情報を含まない範囲を変換する場合は、横書きテキスト領域を指定してください。
- OCR機能を使って英文のPDFを変換したところ、複数の英単語がつながって変換されてしまいました。
- OCR機能では、既定の言語として「日本語」が設定されています。この状態で日本語以外の言語で記述された文書を変換すると、英単語の区切りがされす、すべてつながった状態で変換される場合があります。
そのような時は、OCR処理条件で言語を切り替えて変換することで改善される可能性があります。