9.1.5 抽出した漢字からバリエーションセレクタを削除する
狙い・効果
漢字の直後に置いて異体字を表示させる特殊なUnicode文字「バリエーションセレクタ」を抽出した文字列から削除します。
処理の概要
文字抽出抽出する文字列の中からバリエーションセレクタを削除します。
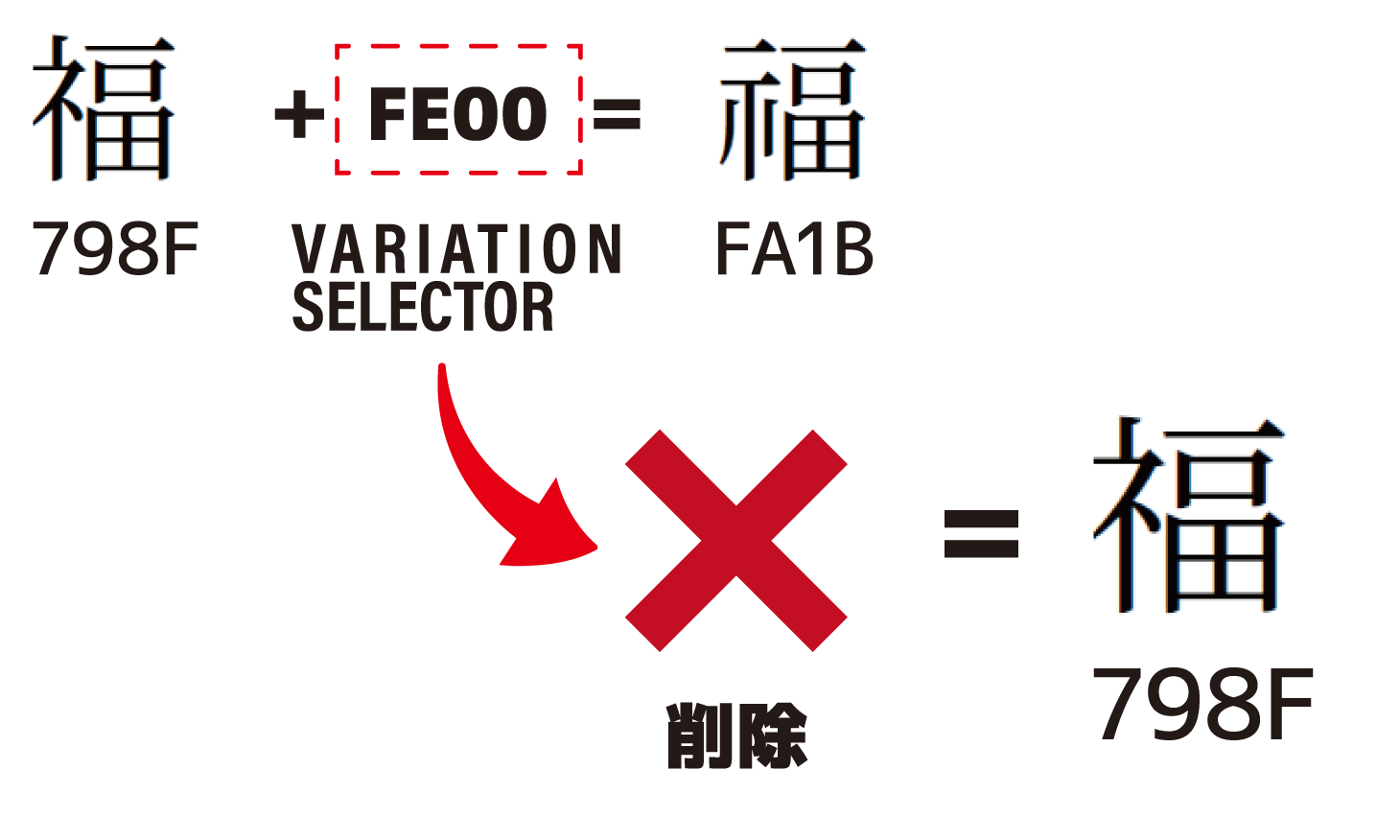
バリエーションセレクタは漢字の直後に挿入する特殊なUnicode文字で、同じ漢字の異体字を表示させることができます。UnicodeではFE00~FE0Fで表されます。
バリエーションセレクタを使って異体字を描画していた場合、バリエーションセレクタが削除されると、そこの漢字は異体字ではなくなります。
PtlParamExtractText.setUnicodeToRemove()でAHEXTRACTTEXT_UNI_VARIATION_SELECTORを指定することで、抽出する文字列からバリエーションセレクタを削除します。削除する文字種はint型で表したフラグで指定します。
サンプルプログラムでは、入力PDFの指定したページ全体から文字列を抜き出す際に、バリエーションセレクタを削除する・しないを切り替えた上で抽出します。
『PDF Tool API』の主な機能
- PtlParamExtractText.setUnicodeToRemove(int flag): 抽出する文字列の中から指定されたUnicodeを削除。指定に用いる列挙型定数は「9.1.1抽出する文字に含まれた全角スペースを半角スペースに置き換える」を参照してください。
プログラム例
package cookbook;
import java.io.BufferedWriter;
import java.io.PrintWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.charset.StandardCharsets;
import jp.co.antenna.ptl.*;
public class ExtTextWithRemovingVariationSelector {
// そのクラスのusageを表示する関数
private static void printUsage() {
System.out.println("usage: java ExtTextWithRemovingVariationSelector"
+ " in-pdf-file out-text-file"
+ " page-to-extract rem-variation-selector");
System.out.println("--以下の各文字に対して、[0:削除しない 1:削除する]を選択--");
System.out.println("rem-variation-selector : 異体字セレクタ");
System.out.println("rem-replacement-character : 置換文字");
System.out.println("rem-all : 指定可能な全ての特殊文字");
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 4) {
printUsage(); // usageメッセージの表示
return;
}
// コマンドライン引数の読み取り・判定
// 出力PDFの名前はあとで渡すためにString型で保存する。
String outputTextURI = args[1];
int pageToExtract = Integer.parseInt(args[2]);
boolean remVariationSelector = false;
int unicodeCharFlag = 0;
//各種削除フラグの読み取り判定
//rem-variation-selector
try {
remVariationSelector = readBoolArgs(args[3],
"rem-variation-selectorは" +
"0か1で指定してください。");
}
catch (IllegalArgumentException ex) {
System.out.println(ex.getMessage());
printUsage(); // usageメッセージの表示
return;
}
//各フラグの論理和をunicodeCharFlagに設定
if(remVariationSelector) {
unicodeCharFlag = unicodeCharFlag | PtlParamExtractText.AHEXTRACTTEXT_UNI_VARIATION_SELECTOR;
}
try(PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument()) {
// PDFファイルをロード
doc.load(inputFile);
try(PtlPages pages = doc.getPages()) {//ページコンテナの取得
// ページコンテナが空かどうか
if(pages.isEmpty()) {
System.out.println("ERROR : ページコンテナが空");
throw new Error("ERROR : ページコンテナが空");
}
//ページ数を取得
int wholePageNum = doc.getPageCount();
//pageToExtractが0ならすべてのページを処理する
if(pageToExtract == 0) {
StringBuilder wholeTextFromPdf = new StringBuilder();
// ページの取得(パラメータindexは0が先頭のため1を引く)
for(int i = 0; i < wholePageNum; i++) {
try(PtlPage page = pages.get(i);
PtlContent content = page.getContent()) { // ページコンテントの取得
System.out.println((i+1) + "ページ目のテキストを抽出します。");
wholeTextFromPdf.append(extractTextSetRemoveUnicodeFlag(unicodeCharFlag, content));
}
}
outputTextFile(outputTextURI, wholeTextFromPdf.toString());
}else {
if(wholePageNum < pageToExtract) { //pageToExtractのエラー処理
...【ExtTextWithRplcIdeographicSpaceToSpace.javaと同じ処理のため省略
・総ページ数よりも大きいページ数を指定した場合のエラー処理】...
}
try(PtlPage page = pages.get(pageToExtract - 1); //指定したページを取得する
PtlContent content = page.getContent()) {
System.out.println(pageToExtract + "ページ目のテキストを抽出します。");
outputTextFile(outputTextURI, extractTextSetRemoveUnicodeFlag(unicodeCharFlag, content));
}
}
}
}
...【GetPDFVersion.javaと同じ処理のため省略
・エラーメッセージ処理と出力】...
}
private static String extractTextSetRemoveUnicodeFlag(int unicodeCharFlag, PtlContent content)
throws IOException, PtlException, Exception, Error {
try(PtlParamExtractText paramExtractText = new PtlParamExtractText()) { // 文字抽出のパラメータクラス。
//setUnicodeToRemoveをパラメータに設定
paramExtractText.setUnicodeToRemove(unicodeCharFlag);
// 文字列抽出
String textFromPdf = content.extractText(paramExtractText);
System.out.println(textFromPdf);
// 抽出した文字列を返す
return textFromPdf;
}
}
/**
* テキストファイルを出力するための関数。
* 出力エンコードはUTF-8を指定する。
* 特に外部からの呼び出しを想定しないためprivateとする。
*
* @param outputTextURI 出力ファイルのURI。
* @param TextFromPdf 出力したいString型変数
*/
private static void outputTextFile(String outputTextURI, String TextFromPdf){
...【ExtractTextSetRect.javaと同じ処理のため省略
・outputTextURIのパスにTextFromPDFの内容をUTF-8エンコーディングで出力する処理】...
}
/**
* 0または1を入力されたargsにより、trueまたはfalseを返すメソッド。
*
* @param args 与えられるコマンドライン引数。0または1でtrueまたはfalseを指定する。
* @param errorMessage argsが0か1でなかった場合に出力されるエラーメッセージを指定する。
* @return argsの数値を読み取った結果を戻す
* @throws java.lang.IllegalArgumentException argsが0か1でなかった場合に発生。
*/
public static boolean readBoolArgs(String args, String errorMessage)
throws IllegalArgumentException {
...【FixUpPDFASetSaveOption.javaと同じ処理のため省略
・0または1を読み取り、boolean型のfalseまたはtrueを返す関数】...
}
}
プログラムファイル名
ExtTextWithRemovingVariationSelector.java
入出力操作の例
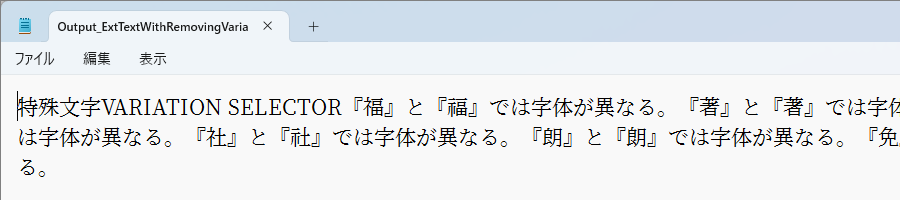
C:\samples>java cookbook.ExtTextWithRemovingVariationSelector usage: java ExtTextWithRemovingVariationSelector in-pdf-file out-text-file page-to-extract rem-variation-selector --以下の各文字に対して、[0:削除しない 1:削除する]を選択-- rem-variation-selector : 異体字セレクタ rem-replacement-character : 置換文字 rem-all : 指定可能な全ての特殊文字 C:\samples>java cookbook.ExtTextWithRemovingVariationSelector Special_letter_sample_VariationSelector.pdf Output_ExtTextWithRemovingVariationSelector.txt 0 1 1ページ目のテキストを抽出します。 特殊文字VARIATION SELECTOR『福』と『福』では字体が異なる。『著』と『著』では字体が異なる。『海』と『海』では字体が異なる。『社』と『社』では字体が異なる。『朗』と『朗』では字体が異なる。『免』と『免』では字体が異なる。 Output text URI :Output_ExtTextWithRemovingVariationSelector.txt -- 完了 --
この操作例にはバリエーションセレクタで表した異体字が入ったPDFを使用しています。(PDFでは異体字を正しく表示するために、"Noto Serif JP" フォントを使用しています)
UTF-8のコード上でバリエーションセレクタを表記していても表示フォント次第では正しく異体字が表示されない点に注意してください。

次の2つの図はバリエーションセレクタを削除した例としなかった例の出力テキストファイルの比較です。表示エディタはWindows11付属のメモ帳で、"Noto Serif JP"フォントを指定しています。
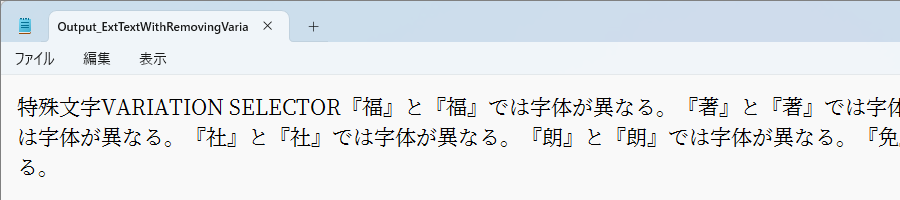
上図ではバリエーションセレクタが削除されているため、同じ漢字が並んでいます。
下図はバリエーションセレクタを残したまま文字を抽出したテキストファイルです。入力PDFと同じ異なる字体の漢字が並んでいるのが確認できます。