9.1.4 抽出した文字からソフトハイフンを削除する
狙い・効果
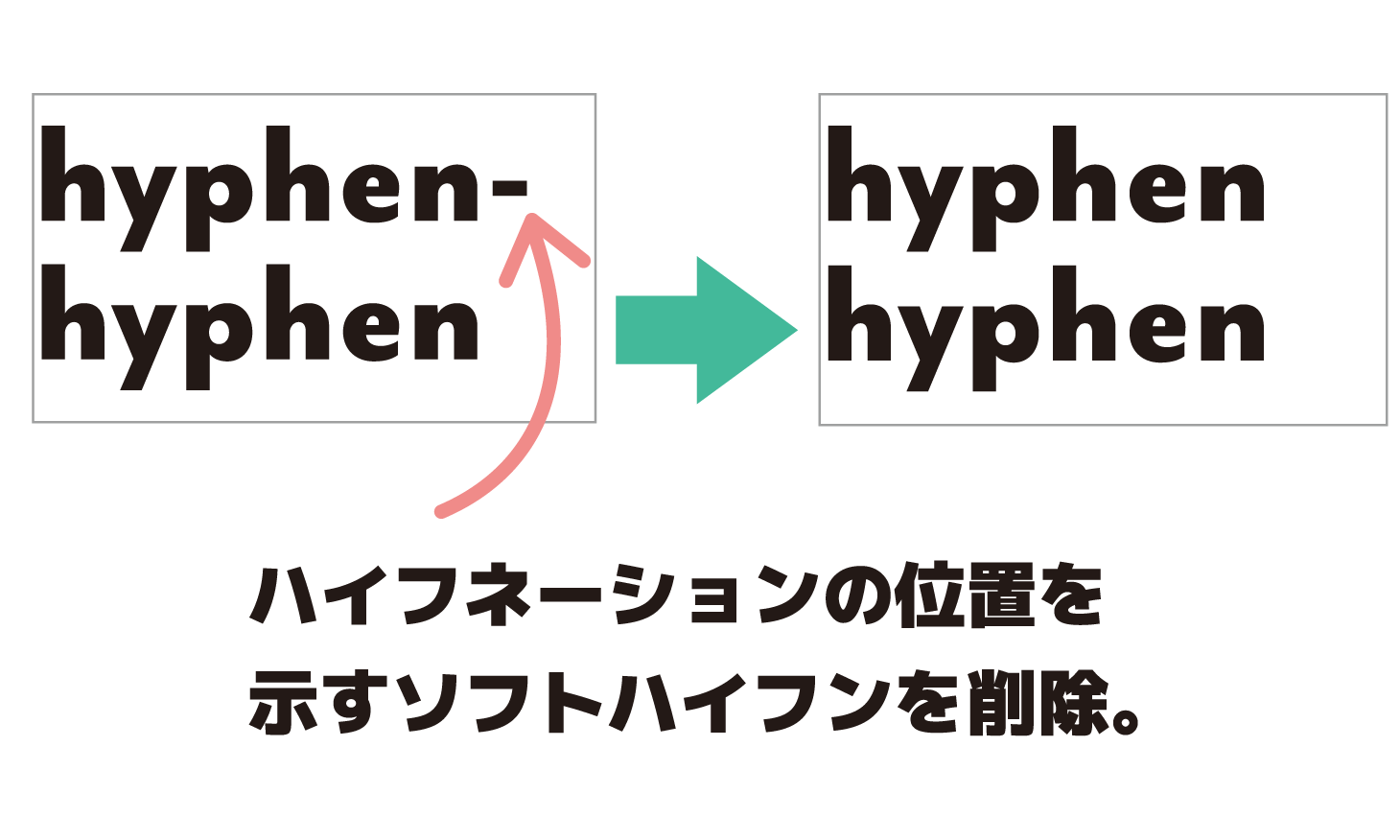
文字抽出抽出する文字列に含まれたソフトハイフンを削除します。
処理の概要
抽出する文字列の中からソフトハイフンを削除します。ソフトハイフンは行末の改行でのみ表示される特殊なハイフンです。Unicodeでは00ADで表される特殊文字で、ウィンドウやテキストボックスの行末でない場合は表示されません。
PtlParamExtractText.setUnicodeToRemove()で
AHEXTRACTTEXT_UNI_SOFT_HYPHENを指定すると、ソフトハイフンは抽出した文字列から削除されます。削除する文字種はint型で表したフラグで指定します。
サンプルプログラムでは、入力PDFの指定したページ全体から文字列を抜き出す際に、ソフトハイフンを削除する・しないを切り替えた上で抽出します。
『PDF Tool API』の主な機能
- PtlParamExtractText.setUnicodeToRemove(int flag): 抽出する文字列の中から指定されたUnicodeを削除。指定に用いる列挙型定数は「9.1.1抽出する文字に含まれた全角スペースを半角スペースに置き換える」を参照してください。
プログラム例
package cookbook;
import java.io.BufferedWriter;
import java.io.PrintWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.charset.StandardCharsets;
import jp.co.antenna.ptl.*;
public class ExtTextWithRemovingSoftHyphen {
// そのクラスのusageを表示する関数
private static void printUsage() {
System.out.println("usage: java ExtTextWithRemovingSoftHyphen in-pdf-file"
+ " out-text-file page-to-extract rem-soft-hyphen");
System.out.println("--以下の文字に対して、[0:削除しない 1:削除する]を選択--");
System.out.println("rem-soft-hyphen : ソフトハイフン");
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 4) {
printUsage(); // usageメッセージの表示
return;
}
// コマンドライン引数の読み取り・判定
// 出力PDFの名前はあとで渡すためにString型で保存する。
String outputTextURI = args[1];
int pageToExtract = Integer.parseInt(args[2]);
boolean remSoftHyphen = false;
int unicodeCharFlag = 0;
//各種削除フラグの読み取り判定
//rem-soft-hyphen
try {
remSoftHyphen = readBoolArgs(args[3], "rem-soft-hyphenは" +
"0か1で指定してください。");
}
catch (IllegalArgumentException ex) {
System.out.println(ex.getMessage());
printUsage(); // usageメッセージの表示
return;
}
//各フラグの論理和をunicodeCharFlagに設定
if(remSoftHyphen) {
unicodeCharFlag = unicodeCharFlag | PtlParamExtractText.AHEXTRACTTEXT_UNI_SOFT_HYPHEN;
}
try(PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument()) {
// PDFファイルをロード
doc.load(inputFile);
try(PtlPages pages = doc.getPages()) {//ページコンテナの取得
// ページコンテナが空かどうか
if(pages.isEmpty()) {
System.out.println("ERROR : ページコンテナが空");
throw new Error("ERROR : ページコンテナが空");
}
//ページ数を取得
int wholePageNum = doc.getPageCount();
//pageToExtractが0ならすべてのページを処理する
if(pageToExtract == 0) {
StringBuilder wholeTextFromPdf = new StringBuilder();
// ページの取得(パラメータindexは0が先頭のため1を引く)
for(int i = 0; i < wholePageNum; i++) {
try(PtlPage page = pages.get(i);
PtlContent content = page.getContent()) { // ページコンテントの取得
System.out.println((i+1) + "ページ目のテキストを抽出します。");
wholeTextFromPdf.append(extractTextSetRemoveUnicodeFlag(unicodeCharFlag, content));
}
}
outputTextFile(outputTextURI, wholeTextFromPdf.toString());
}else {
if(wholePageNum < pageToExtract) { //pageToExtractのエラー処理
...【ExtTextWithRplcIdeographicSpaceToSpace.javaと同じ処理のため省略
・総ページ数よりも大きいページ数を指定した場合のエラー処理】...
}
try(PtlPage page = pages.get(pageToExtract - 1); //指定したページを取得する
PtlContent content = page.getContent()) {
System.out.println(pageToExtract + "ページ目のテキストを抽出します。");
outputTextFile(outputTextURI, extractTextSetRemoveUnicodeFlag(unicodeCharFlag, content));
}
}
}
}
...【GetPDFVersion.javaと同じ処理のため省略
・エラーメッセージ処理と出力】...
}
private static String extractTextSetRemoveUnicodeFlag(int unicodeCharFlag, PtlContent content)
throws IOException, PtlException, Exception, Error {
try(PtlParamExtractText paramExtractText = new PtlParamExtractText()) { // 文字抽出のパラメータクラス。
//setUnicodeToRemoveをパラメータに設定
paramExtractText.setUnicodeToRemove(unicodeCharFlag);
// 文字列抽出
String textFromPdf = content.extractText(paramExtractText);
System.out.println(textFromPdf);
// 抽出した文字列を返す
return textFromPdf;
}
}
/**
* テキストファイルを出力するための関数。
* 出力エンコードはUTF-8を指定する。
* 特に外部からの呼び出しを想定しないためprivateとする。
*
* @param outputTextURI 出力ファイルのURI。
* @param TextFromPdf 出力したいString型変数
*/
private static void outputTextFile(String outputTextURI, String TextFromPdf){
...【ExtractTextSetRect.javaと同じ処理のため省略
・outputTextURIのパスにTextFromPDFの内容をUTF-8エンコーディングで出力する処理】...
}
/**
* 0または1を入力されたargsにより、trueまたはfalseを返すメソッド。
*
* @param args 与えられるコマンドライン引数。0または1でtrueまたはfalseを指定する。
* @param errorMessage argsが0か1でなかった場合に出力されるエラーメッセージを指定する。
* @return argsの数値を読み取った結果を戻す
* @throws java.lang.IllegalArgumentException argsが0か1でなかった場合に発生。
*/
public static boolean readBoolArgs(String args, String errorMessage)
throws IllegalArgumentException {
...【FixUpPDFASetSaveOption.javaと同じ処理のため省略
・0または1を読み取り、boolean型のfalseまたはtrueを返す関数】...
}
}
プログラムファイル名
ExtTextWithRemovingSoftHyphen.java
入出力操作の例
C:\samples>java cookbook.ExtTextWithRemovingSoftHyphen usage: java ExtTextWithRemovingSoftHyphen in-pdf-file out-text-file page-to-extract rem-soft-hyphen --以下の文字に対して、[0:削除しない 1:削除する]を選択-- rem-soft-hyphen : ソフトハイフン C:\samples>java cookbook.ExtTextWithRemovingSoftHyphen Special_letter_sample_SoftHyphen.pdf Output_ExtTextWithRemovingSoftHyphen.txt 0 1 1ページ目のテキストを抽出します。 特殊文字SOFT HYPENSoft hyphen(U00AD) is here"""Thequickbrownfoxjumpsoverthelazydog"Soft hyphen(shy) is here"""Thequickbrownfoxjumpsoverthelazydog" Output text URI :Output_ExtTextWithRemovingSoftHyphen.txt -- 完了 --
操作例では、例文にソフトハイフンが含まれたPDF(下図)を使用しています。
例文の2行目末尾"the"と3行目頭の"lazydog"の間にある記号は一見通常のハイフンのように見えますが、ソフトハイフンです。

ソフトハイフンを削除してテキスト抽出した操作例とそのまま残してテキスト抽出した例の比較です。
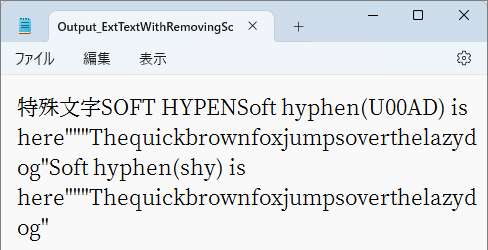 | 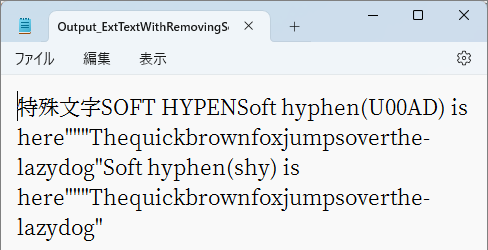 |
| 抽出時にソフトハイフンを削除した出力テキスト | ソフトハイフンが残ったまま文字を抽出したテキスト |
ハイフンの一般的な使い方のひとつに、単語がテキストが収まる矩形の縁(ここではウィンドウの縁)で次行にワードラップする際、語間が不自然に開きすぎるのを防ぎ、語が次行に続くことを明示するというものがありますが、ソフトハイフンは、これをウィンドウの幅の可変で、ハイフンの表示/非表示を切り替えられることが特徴です。
例えば、図9.11は該当箇所に改行が来ないよう、「図:ソフトハイフンが残ったまま文字を抽出したテキスト」のウィンドウの幅を変形させたのでハイフンが表示されません。
