『瞬簡PDF 変換 10』はインターネットに繋がっていなければ使えませんか?
いいえ。インターネットに接続していなくてもお使いいただくことができます。
『瞬簡PDF 変換 10』のインストールが終了しません。
『瞬簡PDF 変換 10』はインストールの際に必要に応じて、Windows用のモジュールなどのインストールを行いますが、このインストール画面が『瞬簡PDF 変換 10』のインストール画面の裏に隠れてしまう場合があります。
このような場合、Alt+Tab で画面を切り替えるか、『瞬簡PDF 変換 10』のインストール画面をドラッグ&ドロップで動かして裏に隠れた画面を表示することでインストールが続行できるようになります。
PDFファイルを対象とした変換(全般)
PDFファイルをリストに登録すると先頭に

アイコンが付きます。
瞬簡PDF 変換 10は、パスワードで保護されたデータの抽出が禁止されているPDFファイル、開くために必要なパスワードが設定されているPDFファイルを処理することができません。そのようなPDFファイルをリストに登録するとファイル名の先頭に
アイコンがついて、そのPDFファイルにパスワードが設定されていることを示します。パスワードを解除するには、
アイコンをダブルクリックするか、ファイルを右クリックして表示されるコンテキストメニューから「パスワードの入力」を選択して表示されるダイアログボックスにパスワードを入力して、これを解除してください。パスワードが解除されると
アイコンの表示が
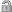
に変化して、これを示します。
PDFファイルを対象に変換を実行すると、[処理エラー]が発生する。
本製品で処理エラーが発生する場合は、お使いのファイルや実行環境などによりさまざまな原因が考えられます。以下をご参考にしてください。
- 変換元ファイルが画像のみのデータである場合は、OCR処理が働くためメモリー不足でエラーとなる可能性があります。このような場合は、ページ範囲を指定し変換対象のページ数を減らした上で変換してみてください。
- 変換先ファイル形式がOffice 2007-2016文書(docx/xlsx/pptx/)である場合は、メモリー不足でエラーとなる可能性があります。このような場合は、変換条件でメモリーの使用量を増やした上で変換してみてください。
- 変換先に指定したフォルダーに同名の文書が存在していてWordなどで開いている場合は、変換時に上書きができないためエラーとなります。このような場合は、あらかじめそれらの文書を閉じてから変換を行ってください。
- 変換元ファイルが本製品で扱えないファイルである場合は、エラーとなる可能性があります。PDFファイルを作成したソフトウェアによっては、本製品が処理できない構造を持つ場合があります。
PDFファイルを対象に変換を実行すると文字が「?」と変換される。
フォントの埋め込みを指定して作成したPDFファイルでは、文字が描画オブジェクトとして格納されます。この場合、同時に文字の外観と文字コードを関連づけしたデータが格納されていれば、Word文書などへ変換した場合に文字を再現することができます。しかし、PDFファイルを作成したソフトウェアによっては、このような関連づけデータを作成していないことがあり、そのような場合には、「?」などの文字に代替されて変換されます。
こうしたファイルを変換する場合は、以下の手順をお試しください。
①ファイル一覧にPDFを登録して、「OCR設定」の列で「(自動)▼」と書かれた箇所をクリックします。
②表示された一覧から「(常に行う)」を選択します。
③「実行」ボタンをクリックします。
※この方法では、OCRを使用して文字を取得するため一部で文字化けが出る可能性があります。ご了承ください。
PDFファイルを対象に変換を実行すると、線画の部分が一部欠けたようになって変換される。
初期設定では、罫線で囲まれた領域を表として変換します。このため変換対象となるPDFファイル中で線画の一部に矩形が使用されているような場合には、矩形の部分だけが表(セル)に変換され、線画が正しく再現できないことがあります。このような場合には、下記をお試しください。
① 変換設定ダイアログのオプション「表をセルに変換しない」を有効にして変換してみてください。なお、処理対象となるPDFファイルに表と線画の混在するようなレイアウトである場合、「表をセルに変換しない」オプションにするとセルの変換がされなくなります。
② 変換詳細ボタンをクリックして「変換の詳細設定」画面を表示させます。「画像変換の指定」画面で線画として変換したい範囲を指定した上で変換を行ってみてください。
PDFファイルに表示された文字が変換されない。
本製品ではPDFの注釈データを変換の対象外としています。このため、注釈機能(ノート注釈やテキスト注釈など)を使って文字を入力したPDFからはその部分の文字が変換先に渡りません。
これは本製品の仕様となりますので、ご了承ください。
PDFファイルで表示される点線が変換されない。
PDFで点線を表示する場合、内部的に微小なイメージを複数連続してつなげることで点線を表現していることがあります。このような微小なイメージがPDF中に大量にあると、変換に時間がかかったりメモリーの不足を生じる可能性があるため、本製品ではそれらを無視して変換します。このため変換結果に点線が再現できないことがあります。
これは本製品の仕様上の制限となりますので、ご了承ください。
PDFファイルで表示される背景の色や模様が変換されない。
本製品では、PDFでパターンやシェーディングと呼ばれる手法を使って表現される塗りつぶしに対応していません。このため、変換結果に色や模様点線が正しく再現できないことがあります。
これは本製品の仕様上の制限となりますので、ご了承ください。
PDFファイルからWord文書への変換
PDFファイルからWord文書への変換を行った際、大きな画像が正しく変換されない場合がある。
Word文書の最大用紙サイズは558.7mm×558.7mmです。これより大きなサイズの文書を変換しようとすると、Word文書への書き出し時に用紙サイズが、最大用紙サイズに補正されます。変換対象となるPDFファイル中に最大用紙サイズを超えるような画像が使用されている場合、Word文書には変換されません。これは仕様上の制限となります
PDFファイルからExcel文書への変換
PDFファイルからExcel文書の変換を行った際、色が正しく再現されない場合がある。
PDFファイルからExcel文書への変換を行う場合、PDFファイル中で用いている色をExcel文書の標準パレット色に近似することで再現します。このため、用いられている色によっては、Excel文書で正確に再現できない場合があります。
PDFファイルからExcel文書への変換を行う場合、斜線が変換されない場合がある。
PDFファイルからExcel文書への変換を行う場合、セルにマッチする斜線をセルの斜線として変換します。これ以外の斜線は無視しますので、折れ線グラフのように縦横の罫線と斜め線が混在して表現するようなPDFファイルでは、折れ線部分が正しく変換されない場合があります。このような場合には、変換詳細設定で該当箇所を画像として変換するように指定してください。
PDFファイルからExcel文書への変換を行う際、変換されない描画オブジェクトがある。
Excel文書への変換を行う場合、通常矩形をセルに変換します。しかし、幅が3 Point 未満の矩形はセルとするには無理があるため、無視します。このため、PDFファイル中に細い矩形が連続して描画されているような箇所は、変換されない場合があります。
PDFファイルからExcel文書の変換を実行すると、"0.0"が"0"に変換される。
PDFファイルからExcel文書に変換する場合、得られるセルの内容からセル書式を判断しています。"0.0"は、数字と判断されるため、"0"も"0.0"も等しく数値データ"0"に変換されます。
PDFファイルからExcel文書への変換を行う場合、文字の下線が変換されない場合がある。
PDFファイルからExcel文書への変換を行う場合、文字列の内容によりセルを作成します。文字の下線もセルの罫線に変換しますが、セルの罫線に複数の線種が存在する場合、一番割合の長い線種を優先して設定します。このため、文字の下線が変換されないことがあります(この場合の線種には、"線無しも"含まれます)。
PDFファイルからExcel文書への変換で、複数ページを1シートにまとめる指定が有効にならない。
「複数のページを1シートに変換する」指定は、ひとつの表が複数ページに分かれて記載されているような場合に有効です。この指定は、PDFファイル内の各ページサイズが同じ大きさで、PDFファイルに記述された表の列数・列幅が完全に一致していることが条件となります。そのため、ページ内の表の列幅が他と少し異なっていたり、ページサイズが異なるとシートを分割して変換します。
PDFファイルから一太郎文書またはExcel文書への変換で、画像が変換されない場合がある。
PDFファイル中の線画または画像が記述されている部分には、背景を白で塗りつぶした矩形を同じ位置に重ねて表示している場合があります。PDFファイルからExcel文書または一太郎文書に変換すると、これらの矩形も一緒に変換され画像部分に重ねて出力されるため、元の線画や画像部分が隠されて見えなくなってしまうことがあります。このような場合には、上に重なっている画像を指定して削除するか移動してみてください。
OCR処理を使った変換
DOCX、XLSX、PPTXへOCRを使用した変換を行うと処理エラーになる。
ログインユーザー名に2バイト文字(全角文字)が含まれている場合、OCRを使用してDOCX、XLSX、PPTXへの変換を行うと処理エラーになります。
このような場合、以下のa. b. いずれかの設定を行う事で回避することができます。
- Windowsで全角文字を使用しないアカウントを作成して、作成したアカウントでログインする
- 現在ログインしているアカウントでTEMPの環境変数を変更する
- CドライブやDドライブなどの直下に tmp 等、半角文字のみを使用したフォルダを作成します
- Windowsの「システムのプロパティ」を表示する
- Windows 8.1/ 10の場合
- Windows のスタートメニューを右クリックして「エクスプローラー(E)」を選択する
- エクスプローラーの画面から「 PC 」を右クリックして「プロパティ」を選択する
- 「システムの詳細設定」をクリックする
- Windows 7の場合
- Windows のスタートメニューを右クリックして「エクスプローラーを開く(P)」を選択する
- エクスプローラーの画面から「コンピューター」を右クリックして「プロパティ」を選択する
- 「システムの詳細設定」をクリックする
- 「システムのプロパティ」画面で「詳細設定」タブ内の「環境変数(N)」をクリックする
- 「"ユーザー名"の環境変数(U)」欄にある変数 TEMP をクリックして「編集」をクリックする
- 「ユーザー変数の編集」画面が表示されたら「変数値(V)」欄内の文字を削除して 1.で作成したフォルダの場所を入力して「OK」を押す
(Cドライブの直下に tmp フォルダを作成した場合 C:\tmp を入力)
- 次に「"ユーザー名"の環境変数(U)」欄にある変数 TMP をクリックして「編集」をクリックする
- 上記5.と同じように「変数値(V)」欄内を変更して「OK」を押す
- 「環境変数」画面で「OK」をクリックして画面を閉じる
- 表示されている画面を全て閉じる
以上a. b.いずれかの方法を行う事で本現象を回避することができます。
なお、本現象については今後の改訂版にて修正を予定しています。
イメージスキャナーを使って紙文書を取り込んで作成したPDFファイルをOCR処理した際、処理エラーが発生する場合がある。
瞬簡PDF 変換 10を使って文字が画像化されたPDFファイルから変換する場合、いったんPDFファイルのページ全体を画像に変換し、これを対象としてOCR処理します。この場合、画像解像度(DPI)の値を高く指定しているとメモリを多量に消費するために画像化に失敗することがあります。このようなときには、[OCR設定]ボタンをクリックして表示される「OCR設定」ダイアログの[DPI値]の値を小さく設定した後、処理してみてください。ただし、この値を低くし過ぎると認識率が低下します。スキャン対象となった画像にもよりますが、一般的に300~400dpiの範囲で指定するのが適当です。
イメージスキャナーを使って紙文書を取り込んで作成したPDFファイルをOCR処理した際、文字化けがひどく期待した結果が得られない。
瞬簡PDF 変換 10で文字が画像化されたPDFファイルから変換する場合、いったんPDFファイルのページ全体を画像に変換してからOCR 処理します。この場合、元のPDFファイルの状態により画像化された文字認識率が左右されます。スキャンされたPDFファイルの画像の品質が元々低い場合には、OCR処理によって文字を認識することが困難です。状態にもよりますが、おおよそ200dpiを境にこれ以下の解像度の場合、文字認識が、かなり低下します。そうでない場合には、[OCR設定]ボタンをクリックして表示されるダイアログの[DPI値]で、高解像度に設定することで改善する場合があります。ただし、解像度を高くすると処理にメモリや処理時間を大量に必要としますので、注意してください。
OCR処理によって出力されるPDFファイルのサイズが、処理対象となるファイルより大きい。
処理対象となるのが画像ファイルの場合、ファイルのフォーマットによっては、処理対象となる画像ファイルより出力されるPDFファイルのほうが、ファイルサイズが大きくなる場合があります。(特にJPEGファイルの場合)
処理対象がPDFファイルの場合、ページをいったん画像に変換し、その画像をOCR処理し、得られたテキストと変換した画像とでページが構成されたPDFファイルとして出力します。そのため、PDFファイルの内容や、OCR処理オプションのDPIの設定によっては、出力されるPDFファイルのほうが、ファイルサイズが大きくなる場合があります。一般にDPIの設定値が大きいほど、出力されるPDFファイルのサイズが大きくなります。
[スキャナーから追加する]を選択するとエラーが表示されて次に進めない。
[スキャナーから追加する]を選択したときに以下のエラーが表示された場合は、お使いのパソコンにスキャナードライバーがインストールされていない可能性があります。 スキャナーのCDまたはメーカーの製品ページから機種とOSに適合したスキャナードライバーを取得し、インストールしてください(スキャナードライバーの詳細は、各スキャナーメーカーにお問い合わせください)。
「ソースの選択」画面でスキャナーを選択するとエラーが表示されて次に進めない。
「ソースの選択」画面でスキャナーを選択したときに以下のエラーが表示された場合は、スキャナーがパソコンに接続されていない可能性があります。その場合は、いったんエラー画面を閉じ、スキャナーがお使いのパソコンに接続されているかを確認してから、再度[スキャナーから追加する]の操作を行ってみてください。
複数ライセンスの詳細をお教えください。何本から何本までが、いくらとか。
複数ライセンスの価格はオープンプライスとなります。詳しい価格やお申し込みはライセンス販売の価格とお申し込みページからお問い合わせください。
⇒
ライセンス販売の価格とお申し込み ページ 『瞬簡PDF 変換 10』 ボリュームライセンスについて、会社内で購入を検討しているのですが、
1.)最初にボリュームライセンスにて、10ライセンス購入後、追加でライセンスのみを購入することは出来るのでしょうか?
2.)また、購入経路はどのような方法になりますでしょうか?
はい。後からライセンスを追加していただくことができます。ただし、ボリュームライセンスは10ライセンス単位での追加となります。
ご購入は、弊社の直販もしくは販売店様からお取り寄せいただくことになります。追加される場合は、お持ちのライセンス証書をこちらで確認する必要がありますのでお持ちのライセンスの情報を提供していただくことになります。