アンテナハウス株式会社
XMLとは情報を表現するための新しい方法です。XMLでは、これまでバイナリー形式というプログラムでしか処理できない形式で表現していた情報を、テキスト形式で表現します。
テキスト形式は、人間でも理解できる文字で情報を表現しますので、情報を処理するプログラムと情報自身を独立にすることができます。バイナリ形式の情報は、専用のプログラムで処理するしかなかったのですが、テキストになることで情報の共有や柔軟な加工が可能になります。
特定のデータ構造とは、次のような表形式データであればレコードとフィールドです。
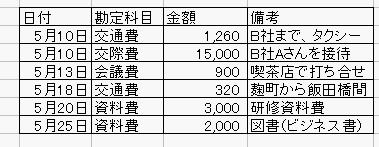
次の例は、上の表をXMLで表現したものです。次の例で<表>、<データ>というようなタグセットを規定する仕様がひとつの応用仕様です。
<表>
<データ record="1">
<日付>5月10日</日付>
<勘定科目>交通費</勘定科目>
<金額>1,260</金額>
<備考>B社まで、タクシー</備考>
</データ>
<データ record="2">
<日付>5月10日</日付>
<勘定科目>交際費</勘定科目>
<金額>15,000</金額>
<備考>B社Aさんを接待</備考>
</データ>
<データ record="3">
<日付>5月13日</日付>
<勘定科目>会議費</勘定科目>
<金額>900 </金額>
<備考>喫茶店で打ち合せ</備考>
</データ>
<データ record="4">
<日付>5月18日</日付>
<勘定科目>交通費</勘定科目>
<金額>320 </金額>
<備考>麹町から飯田橋間</備考>
</データ>
<データ record="5">
<日付>5月20日</日付>
<勘定科目>資料費</勘定科目>
<金額>3,000</金額>
<備考>研修資料費</備考>
</データ>
<データ record="6">
<日付>5月25日</日付>
<勘定科目>資料費</勘定科目>
<金額>2,000</金額>
<備考>図書(ビジネス書)</備考>
</データ>
</表>上の例では、<表>、<データ>などがタグです。<...>が開始タグ、</...>が終了タグ。
XML文書の基本構成単位は要素です。要素は、開始タグ、終了タグ、内容からなります。
ひとつの要素は。
<要素型名>要素の内容</要素型名>
例外は、内容をもたない要素である「空要素」です。例えば、HTMLで、横線を指定する<hr>のようなタグは内容を持ちません。XMLでは、<hr></hr>と書くか、
<hr />と書きます。2つの表記方法は同等です。
XMLの基本仕様で要素型名に使える文字の種類が規定されています。半角アルファベット、漢字、ひらがな全角カタカナなどを使うことができます。しかし、全角アルファベット、半角カタカナを要素型名に使うことはできません。
要素には属性を持たせることができ、属性には属性値を指定できます。属性の指定は開始タグまたは空要素タグの中でのみ使用できます。
属性の記述形式:
<要素型名 属性名="属性の値" ...(属性の数だけ繰返し)><データ record="1">では、record が属性名、「1」が属性の値です。
属性の順序は特に意味がありません。また、何を属性にし、何を要素にするかはXMLの応用仕様を設計する人の自由です。例2の(a)、(b)の2つの表現方法はXMLの基本仕様ではどちらも許されます。
<paragraph font-name="MS明朝" font-size="12point">
段落の文字のフォントは明朝で、サイズは12ポイントです。
</paragraph>
<paragraph>
<font-name>MS明朝</font-name>
<font-size>12point</font-size>
段落の文字のフォントは明朝で、サイズは12ポイントです。
</paragraph>XMLの本文はテキスト(文字)です。但し、各種の符号化方式を使用することができますのでメモ帳などのプレーンテキスト・エディタで正しく表示できるとは限りません。
イメージ図形などのバイナリ形式ファイルは、通常は外部実体と言うもので定義し、本文中から実体参照します。
XML文書の先頭にはXML宣言を配置します。
XML宣言は必須ではありませんが、例えば文字符号化方式として、Shift_JIS等を使うときは必要です。省略すると、UTF-8またはUTF-16と見なされます。
<?xml version="1.0" encoding="Shift_JIS" ?>上の例は、次のツリーで表せます。
表 -+- データ -+- 日付 | +- 勘定科目 | +- 金額 | +- 備考
XML文書は物理的には実体という記憶単位(ファイルなど)から構成されます。XML文書には必ず文書実体という実体が一つあり、ほかの実体は文書実体からたどることができます。
正しいXML文書には、「Well Formed」(整形式)XML文書と「Valid」(妥当な)XML文書の2種類があります。
<?xml version="1.0">
<!DOCTYLE 挨拶 SYSTEM "hello.dtd">
<挨拶>
<朝の挨拶>
おはようございます。
</朝の挨拶>
<昼の挨拶>
こんにちは。
</昼の挨拶>
<夜の挨拶>
こんばんは。
</夜の挨拶>
</挨拶>
上の文書では、<挨拶>から</挨拶>の部分が、文書インスタンスになります。
大雑把に言って次の3つの条件を満たすものがWell Formed(整形式)XML文書です。
<root>
<section>セクション1
<paragraph>段落1-1</paragraph>
<paragraph>段落1-2</paragraph>
</section>
<section>セクション2
<paragraph>段落2-1</paragraph>
<paragraph>段落2-2</paragraph>
</section>
</root>
<root>
<section>セクション1
<paragraph>段落1-1</paragraph>
<paragraph>段落1-2</paragraph>
</section>
<section>セクション2
<paragraph>段落2-1</paragraph>
<paragraph>段落2-2</section></paragraph>
</root> (正しくない理由)
<paragraph>の終了タグの前に<section> の終了タグがあります。
Wellformedであって、さらに、「従うべき型」が指定され、その型にあてはまっているのがValidなXML文書です。
<!DOCTYPE xxxx ... >」を配置し、xxxxのところでXML文書が「従うべき型名」を指定します。
注)最近は、型(構造)定義に、「RELAX」や「XMLSchema」が提案されています。
実体(ファイルなど)を読んでXMLの仕様に照らして文法的に正しいかどうかを確認し、アプリケーションに渡す機能をもつものがパーサーです。
パーサーではWellformed(整形式)基準に適合しているかだけを検証する機能をもつWellformed(整形式)パーサーと、Valid(妥当性)基準に当てはまるかを検証する機能をもつValidity(妥当性)検証パーサーがあります。
妥当性検証パーサーは、まず、文書型宣言で指定したDTDを読んで検証します。さらにXML文書インスタンスがそのDTDに従っているか否かを検証します。
| 改訂日 | 改訂内容 |
|---|---|
| 2024年09月17日 | マークアップを変更。現在のウェブサイトに沿う形に変更した。 |
| 2017年4月26日 | マークアップを変更。W3CのHTMLバリデータで正しいHTMLになるように修正した。 |
| 2001年4月17日 | XMLの意味と基本仕様と応用仕様の区別について追記。 |
| 2000年9月21日 | XML文書の構造の項目を追加 |
| 2000年6月26日 | 初版設定 |