- PDFからテキストを抽出
- テキストの抽出順を指定
- テキストを修正して保存
- HTML形式にも保存

PDFのテキストを正しい順序で抽出できる!!
『PDF Advanced Extractor』は、PDFのテキスト/表/画像データに正しい順序をつけて抽出できる専用ツールです。
テキスト抽出時のトラブルに困っていませんか?
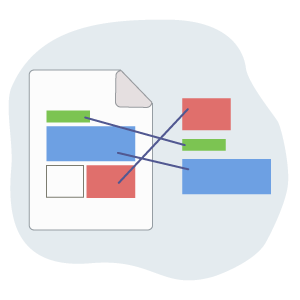
抽出したテキストの順番がバラバラ…
取り出したテキストを並べ替えないと使えない…
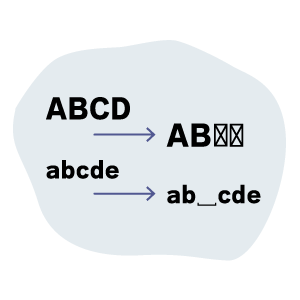
PDF上の見た目どおりに抽出されない
文字化けしたり、不要な余白が入ってしまう…
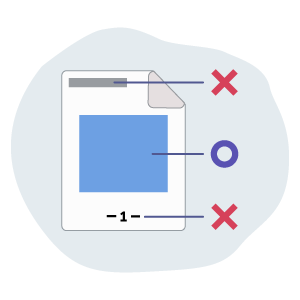
余計なものまで抽出されてしまう
柱やノンブルなど、本文に関係しないテキストは除外したい…
PDF Advanced Extractorにお任せください!
PDFからのテキスト抽出を簡単・正確に!
『PDF Advanced Extractor』は、テキスト抽出時のトラブルを解消する、ユーティリティ・ソフトウェアです。
PDFから欲しいテキスト情報を正確に取得して、PDFの再利用を快適に! 業務の効率化に役立ちます。


 アノテーションツールで利用可能なテキスト形式で保存
アノテーションツールで利用可能なテキスト形式で保存
機械学習に利用するデータの収集をお助け!PDFからアノテーションツールで利用可能な形式でデータを取り出し、保存できる機能を搭載しました。
広汎なテキスト抽出のニーズに対応
PDF Advanced Extractor
主な機能
 テキスト範囲と抽出順を自動で設定
テキスト範囲と抽出順を自動で設定
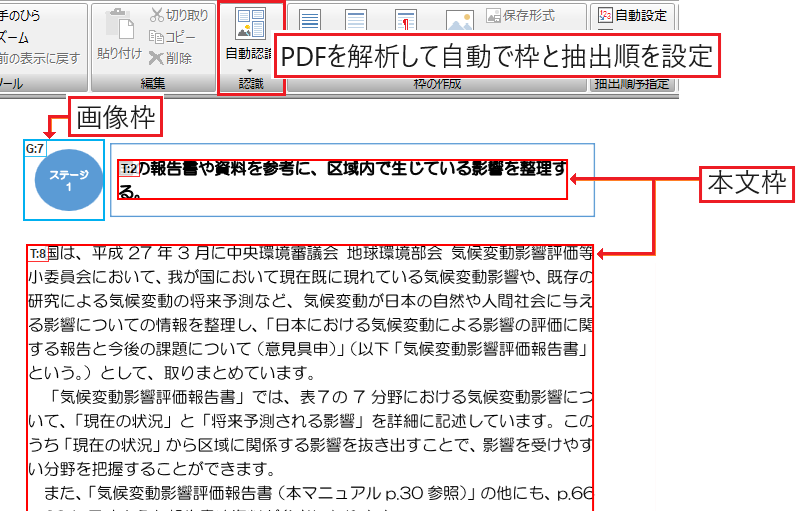
PDFのページからテキストや画像の範囲を自動認識して枠を作成。それぞれの枠に抽出順を設定できます。
すべてのページに一括で枠の自動作成を行うこともできます。
抽出する順序をマウスで簡単に変更
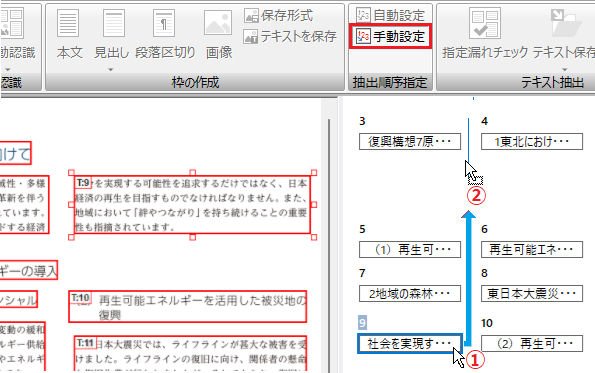
テキストや画像の枠をマウスでドラッグして、抽出する順序を簡単に変更できます。
抽出順序が違っても少ない手間でスピーディな修正が可能です。
テキストの誤りを直接修正
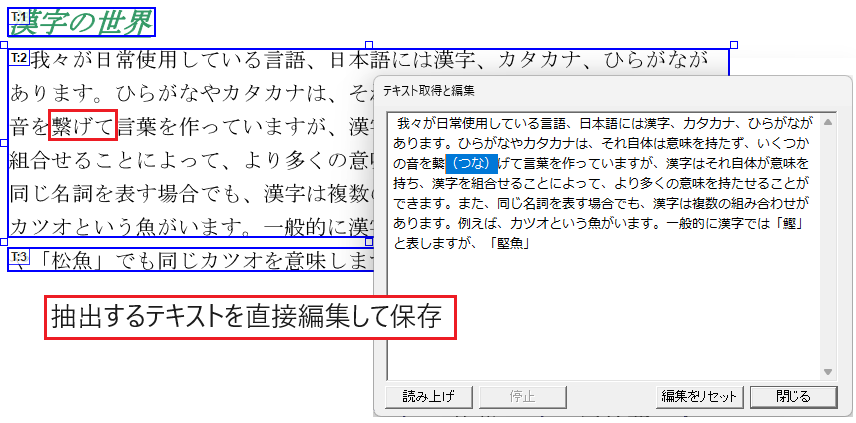
画面上で抽出結果を確認し、誤りがあれば直接修正できます。テキストの文字化け/文字落ち/余分な空白有無などを事前に確認し、その場で修正してからファイルに保存できます。
抽出結果を任意の形式で保存
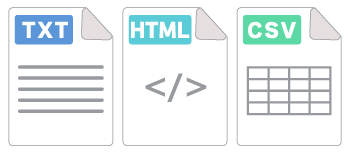
PDFからテキスト/表/画像を抽出し、任意の形式で保存できます。
選択できる形式はプレーンなテキストファイル、HTMLタグ付きファイル、CSVファイルがあり、用途に応じて保存し、活用できます。
機能の追加・改善により、さらに使いやすくなりました!
新規追加・改善機能
お知らせ
-
改訂情報2026年 5月 21日
-
PDF Advanced Extractor V1.1 改訂3版(MR3)を公開しました。
→ 改訂情報ページ
-
改訂情報2026年 5月 14日
-
PDF Advanced Extractor V1.1 改訂2版(MR2)を公開しました。
→ 改訂情報ページ
-
改訂情報2024年 12月 24日
-
PDF Advanced Extractor V1.1 改訂1版(MR1)を公開しました。
→ 改訂情報ページ
-
改訂情報2023年 11月 10日
-
PDF Advanced Extractor V1.1 初版(R1)を公開しました。
→ 改訂情報ページ
-
お知らせ2023年 4月 11日
-
4月25日(火)開催『PDF Advanced Extractor V1.0』ウェビナーのお知らせを掲載しました。

※終了しました YouTube動画
-
改訂情報2023年 2月 28日
-
PDF Advanced Extractor V1.0 初版(R1)を公開しました。
関連情報
お問い合わせ
- 電子メール
- sis@antenna.co.jp