PDF Advanced Extractor機能紹介:テキスト抽出の補完機能
文字と枠の重なりを設定
枠に対して文字の領域が重なる比率(%)を指定することにより、同じ文字が隣接する枠から重複して抽出されないようにします。

指定サイズ以下の文字を除外
ふりがな(ルビ)や注釈文字など、テキスト抽出時に不要となる小さな文字を除外できます。
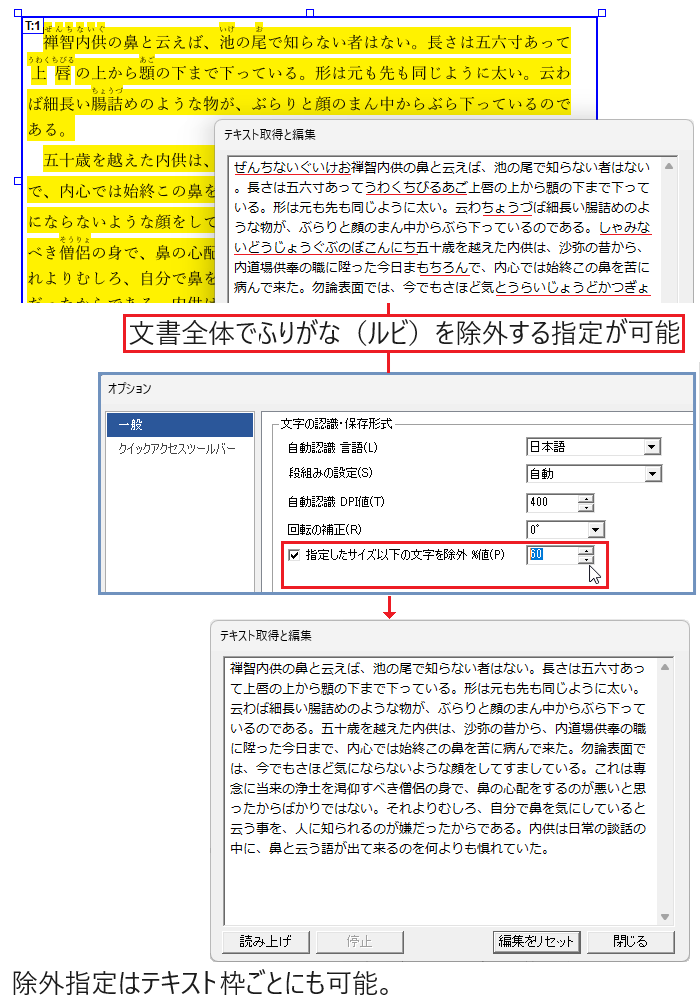
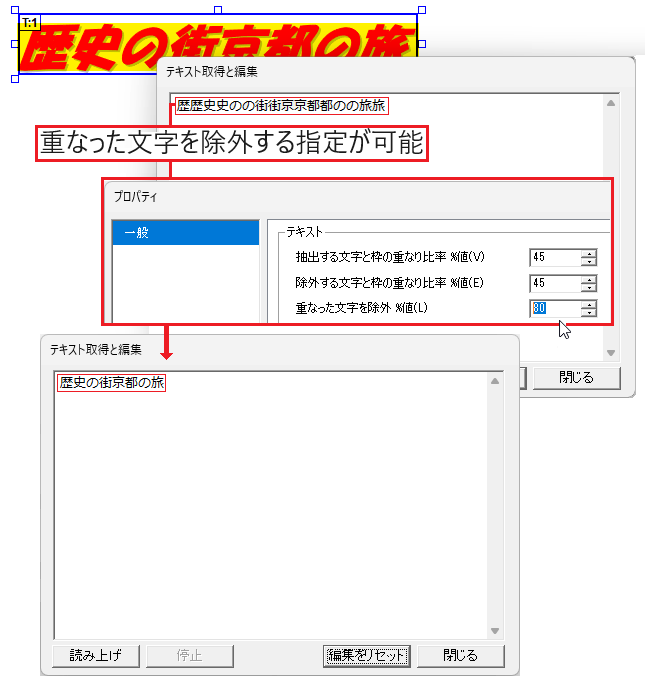
重なった文字を除外
PDFによっては同じ文字を重ね、少しずつ位置をずらして表示することで太字に見せている場合があります。このようなとき、重なった文字を重複して抽出しないように除外できます。
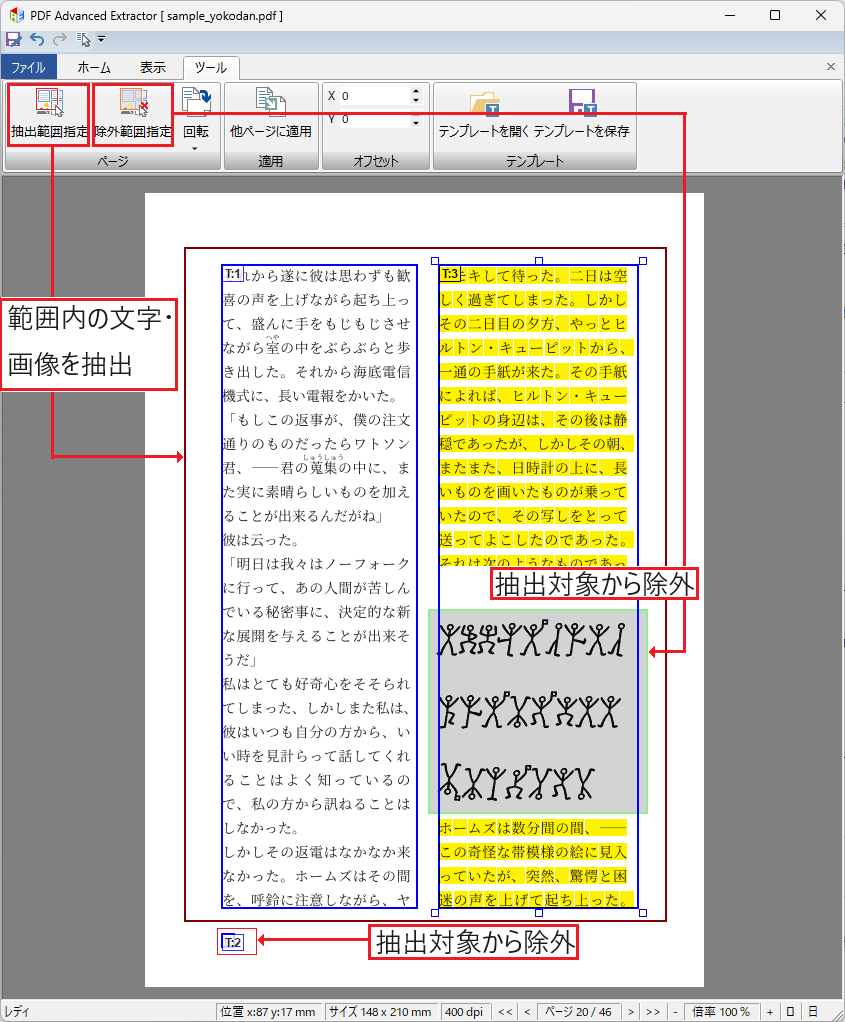
ヘッダー・フッターを除外
ページ上にテキストや画像を抽出する範囲を設定することで、ヘッダー・フッター(柱)やページ番号(ノンブル)など利用しないテキストを抽出対象から除外できます。
抽出範囲の指定は他のページに対しても一括で適用できます。
抽出に使える便利な機能
テキスト抽出を簡単にする便利な機能を多数搭載しています。
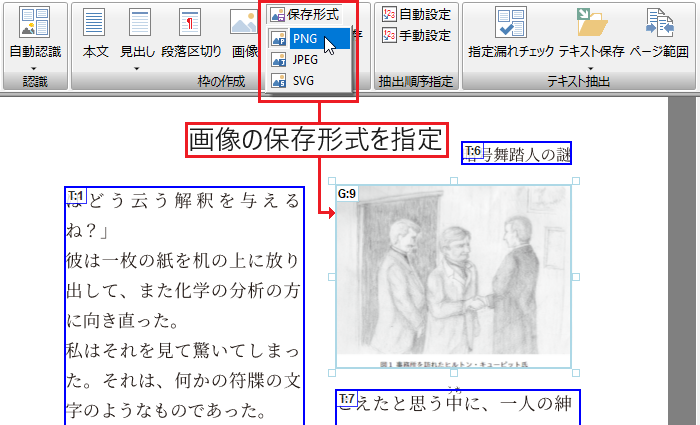
画像データとして保存
画面上で任意の範囲を選択し、画像データ(JPEG/PNG/SVG)に保存できます。表やグラフなどの画像化に便利です。
画像化された文字の抽出
OCR処理により画像化された文字を認識して、通常のテキストデータと同様に抽出できます。
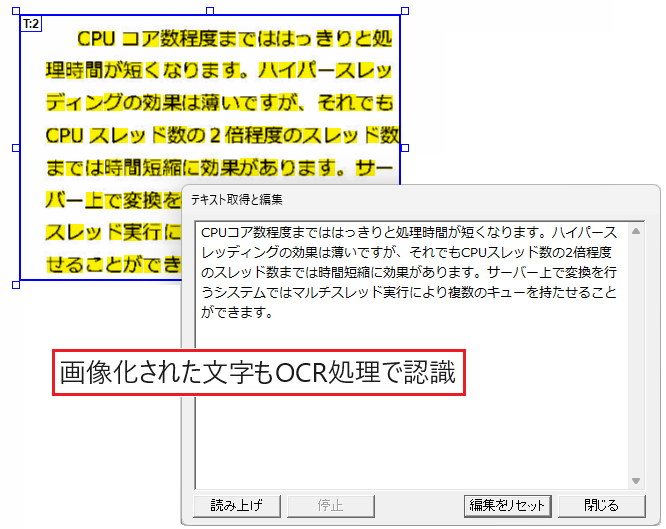
※OCR処理による文字認識はオプションでオン/オフを切り替えられます。
欧文テキストのスペース補填
PDFファイルに欧文テキストが埋め込まれている場合は単語間のスペースを自動的に補って抽出します。
その他の便利機能
- 複数ページに同一のレイアウトが連続して使用されているような場合(帳票形式のPDFなど)、任意のページでテキストや画像の範囲を設定し、別のページに一括適用できます。
- 類似のレイアウトが使用されたPDFファイルが複数ある場合、いずれかひとつのPDFでテキストや画像の範囲を設定してテンプレートファイルに保存し、別のPDFに適用できます。
- PDFに格納されて、クリッピングパスで非表示に設定されているテキストを抽出するかどうか指定できます(オプション)。
- 画面上の操作は、マウス以外にキーボードを使ったショートカットキーでも実行できます。操作のやり直しや元に戻す操作、コマンドの解除などをスムーズに行えます。