トップページ > デスクトップ製品情報 > 瞬簡PDF 変換 10 製品トップ
『瞬簡PDF 変換 10』の変換機能をMicrosoft Office (Word、Excel、PowerPoint) に組み込むことで、直接PDFを読み込むことができます。
インストールを行うと、WordやExcel、PowerPointのツールバーに「PDFを変換」ボタンが組み込まれます。このボタンを押してPDFファイルを選択することで簡単にPDFファイルを開き編集することができます。
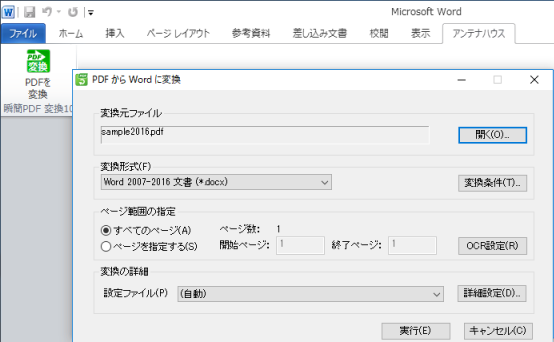
※アドイン機能はMicrosoft Office 2010 以降のバージョンでのみ動作保証いたします。
『瞬簡PDF 変換 10』ではスキャナーから取り込んだような画像ファイル、または画像PDFに対して、OCR(文字認識)処理を行い、その結果を透明テキストとして埋め込んだPDFを作成できます。これにより文字情報を含まないPDFファイルでも、本文の文字列検索が可能になります。
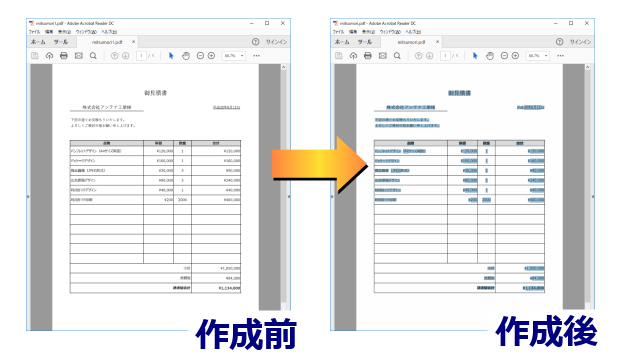
また、OCR結果をテキストファイルとして保存することもできます。
※OCR処理によって出力されるPDFファイルのサイズが、処理対象となる元のファイルより大きくなる場合があります。
これはページを一旦OCR処理に適した解像度の画像に変換し、その画像と処理結果のテキストとで構成されたPDFファイルを出力するためです。
そのため、PDFファイルの内容や、OCR処理オプションのDPIの設定によっては、出力されるPDFファイルのほうが、ファイルサイズが大きくなる場合があります。一般にDPIの設定値が大きいほど、出力されるPDFファイルのサイズが大きくなります。
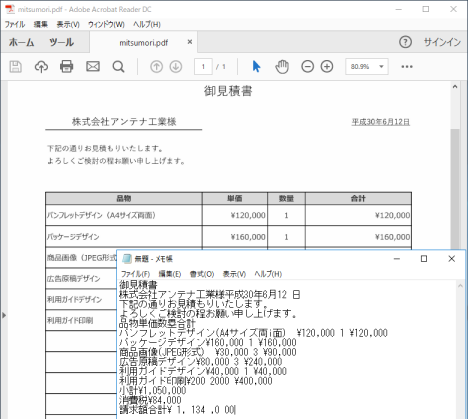
PDFからテキストや画像を取り出してそれぞれファイルに保存することができます。これにより、PDF内のデータを別のソフトに取り込んで再利用することが可能になります。
データ抽出機能は以下のような特長があります。
複数のPDFを登録しておくことで、一括でデータの抽出を行うことができます。
複数ページに渡ったPDFデータの場合、3ページ目のテキストまたは画像のみ取り出すといった、ページを指定してのデータ抽出も できます。
テキスト抽出時に以下のエンコードが指定可能です。
取り出したテキストに改行コードを付加するかどうか指定ができます。
※
改行コードはCRLF(Win)固定になります。
PDFに含まれる画像を抽出して保存できます。画像抽出を行った場合、取り出された画像はビットマップ形式(BMP)またはJPEG形式(JPG)、PNG形式(PNG)のいずれかとなります(指定することはできません) 。



