トップページ > デスクトップ製品情報 > 瞬簡PDF 変換 11 製品トップ > PDFを編集可能なOffice文書に変換!
『瞬簡PDF 変換 11』はPDFファイルからWordやExcel、PowerPoint、一太郎形式のファイルへ、簡単な操作で変換可能です。
WordではPDFを直接開くこともできます。しかし、元のPDFのレイアウトが崩れてしまいなかなか思うような編集ができない場合も多くあります。そのような場合でも、『瞬簡PDF 変換 11』を使用することでPDFのレイアウトを保持したまま変換を行うことができます。
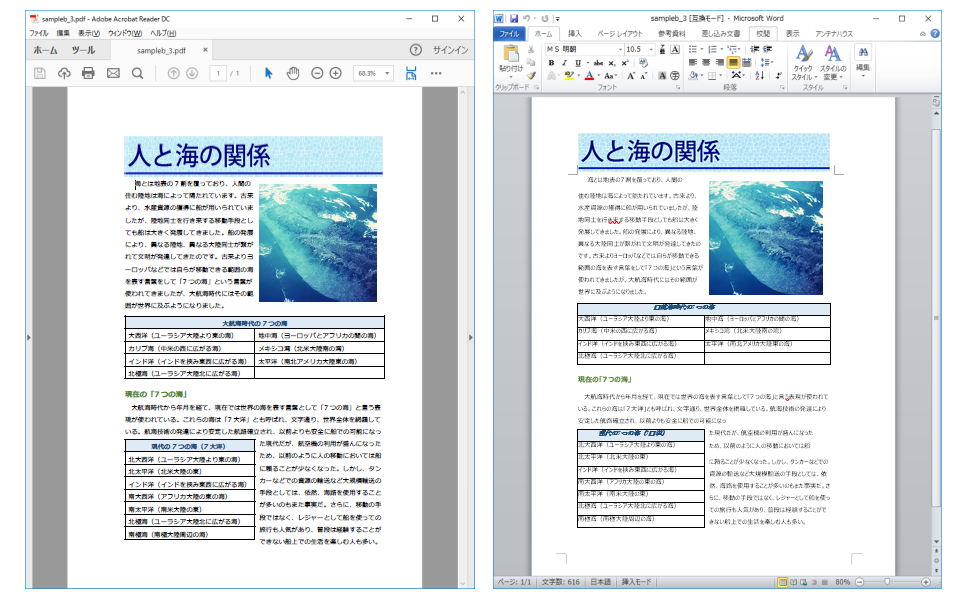
Wordから直接読み込んだ場合と『瞬簡PDF 変換 11』で変換した場合の比較。
上記PDFをWordで直接読み込んだ結果(左)と『瞬簡PDF 変換 11』で変換した結果(右)。
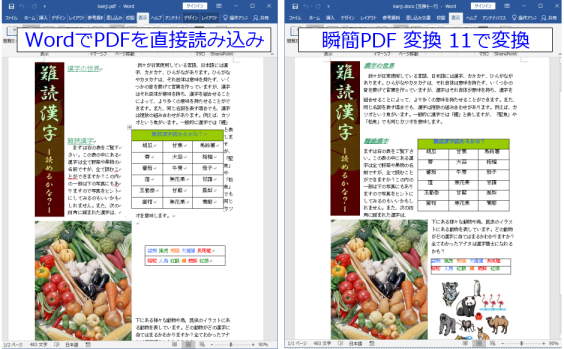
ファイルにもよりますが、上記のようにWordで直接PDFを読み込むと文字や表、画像の位置などがずれるなど、大きくレイアウトが崩れてしまうようなファイルがあります。このような場合、『瞬簡PDF 変換 11』を使用することでレイアウトを変えること無くそのまま編集することができます。
PDFからの変換時に「変換条件」を指定することで、より高精度な変換を行うことができます。
指定できる変換条件は変換先のファイル形式によって異なり、次のような変換条件を指定することができます。
| ファイル形式 | 変換条件 |
|---|---|
| Word 2007-2019 | 標準の変換 |
| レイアウト優先で変換 ※変換先でテキストボックスを配置してレイアウトを再現するため 比較的高い精度でレイアウトを再現できますが、 テキストボックスを多用するため編集がしにくくなります。 |
|
| 罫線をすべて線画に変換する ※PDFで罫線が使用されていた場合、セルの枠線を線画に変換します。 | |
| 変換時のメモリー割り当て 標準 / 多くする / より多くする | |
| Word 97-2003 | 標準の変換 |
| 表をセルに変換する ※変換元PDFの表部分をWordのセルとして変換します。 | |
| 線画を出力する ※変換元PDFの線画部分をWordでも線画として変換します。 | |
| レイアウト優先で変換 | |
| 段落番号を変換する | |
| 下線、取消線を変換する | |
| PDFが縦書きのとき、ワードの文字も縦書き書式に変換する | |
| Excel 2007-2019 | ページサイズと列幅が同じ場合は、複数のページを1シートに変換する |
| 罫線をすべて画像に変換する | |
| 線画・画像を出力する | |
| セルを縦に結合する | |
| 縦書きのテキストボックスを作成する | |
| 変換時のメモリー割り当て 標準 / 多くする / より多くする | |
| Excel 97-2003 | ページサイズと列幅が同じ場合は、複数のページを1シートに変換する |
| 罫線をすべて画像に変換する | |
| 線画・画像を出力する | |
| セルを縦に結合する | |
| PowerPoint 2007-2019 | 各行の末尾で改行する |
| 変換時のメモリー割り当て 標準 / 多くする / より多くする | |
| PowerPoint 97-2003 | 段落番号を変換する |
| 下線を変換する | |
| 一太郎 | 標準の変換 |
| 表をセルに変換する | |
| 線画を出力する | |
| レイアウト優先で変換 | |
| 下線、取消線を変換する |
その他の変換条件
| ファイル形式 | 変換条件 |
|---|---|
| OCR結果をPDFに埋め込む | 元データを画像化してOCRを埋め込む |
| 元データの情報を保持してOCR結果を埋め込む | |
| 画像の品質 高品質 / 中(既定値) / 低(高圧縮) | |
| OCRテキスト形式 | エンコード Windows31J / UTF-8 / UTF-16 / UTF-16(LE) |
| テキスト抽出 | エンコード Windows31J / UTF-8 / UTF-16 / UTF-16(LE) |
| 改行コードを追加する | |
| ページ区切りを出力する |
テキスト情報のないPDFや画像ファイルも、OCR(文字認識)処理により編集可能なOfficeファイルに変換できます。
また、TWAIN対応のスキャナーから直接画像を取り込む機能により、紙原稿も簡単にOfficeファイルへ変換できます。
本製品では、PDFの他に以下の画像形式からの変換に対応します(画像形式によっては内部フォーマットの相違などから正常に 判別・変換できない場合があります)。
OCRとは画像化された文字(紙をスキャナーで取り込んだ文字等)をコンピューター上で扱える文字に変換する機能です。この機能により、従来画像として出力されていた文字を、編集可能な文字として出力します。
またOCR処理時には、あらかじめ解像度(dpi値)・回転や傾きの角度・出力時の日本語フォント/欧文フォントなど、詳細な設定を行った上で変換することもできます。
※OCRを使用した変換では、元の画像の画質によって文字が正しく認識できない場合があります。文字を正しく認識させるためには次のような画像がお勧めです。
「OCR結果の補正」機能は、画像化されたPDFファイルの変換を行う際に、テキスト・表・画像にしたい箇所をそれぞれ変換前に設定することで、より正確な変換をサポートする機能です。
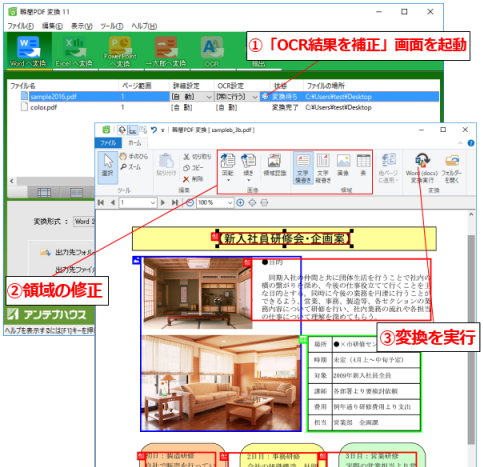
1.「OCR結果を補正」画面の呼び出し
メイン画面で変換先のファイル形式を設定後、ファイルを選択してボタン1つで操作画面を表示します。
2.領域の修正
操作画面では自動的にテキスト・表・画像にする領域を認識し、その範囲を表示します。ここで表示された領域の大きさ・種別・位置などを手動で変更したり、画像の傾き・回転などの補正を行うことができます。
OCR結果の補正機能では次のような設定を行うことができます。
 |
ページの回転を設定することができます。変換対象となるPDFが横に回転しているようなデータを処理する際に設定してください。 設定可能な角度は 回転なし / 自動 / 右90度 / 180度 / 左90度 のいずれかで、「自動」を選択した場合、プログラムがPDF内に含まれる画像を判断して回転を行います。 |
 |
スキャナで取り込んだ画像は傾いていることがあります。そのような場合、角度を指定して傾きを補正することができます。 傾きの補正では -45度から45度までの角度を指定することができますが、「自動」を設定することで、画像の傾き角度を自動的に判断し補正することもできます。 |
 |
OCR処理を行う範囲を自動的に認識します。領域認識を行うことで文字として処理される箇所や表として処理される箇所などが自動的に設定され、範囲を視覚的に認識することができます。 これら領域認識で判定された範囲は任意に変更することもできます。 |
 |
変換対象となるPDF内で横書きのテキストとして認識させたい範囲を指定します。 指定された範囲はOCRの際に横書きテキストとして処理されます。 |
 |
変換対象となるPDF内で縦書きのテキストとして認識させたい範囲を指定します。 指定された範囲はOCRの際に縦書きテキストとして処理されます。 |
 |
変換対象となるPDF内で画像として認識させたい範囲を指定します。 指定された範囲はOCRの際に画像として処理されます。 |
 |
変換対象となるPDF内で表として認識させたい箇所を指定します。 指定された範囲はOCRの際に表として処理されます。 |
3.変換の実行
指定した設定を使って変換を行います。実行する際に変換先ファイル形式の指定や透明テキスト付きPDFの作成などの処理を選択することもできます。
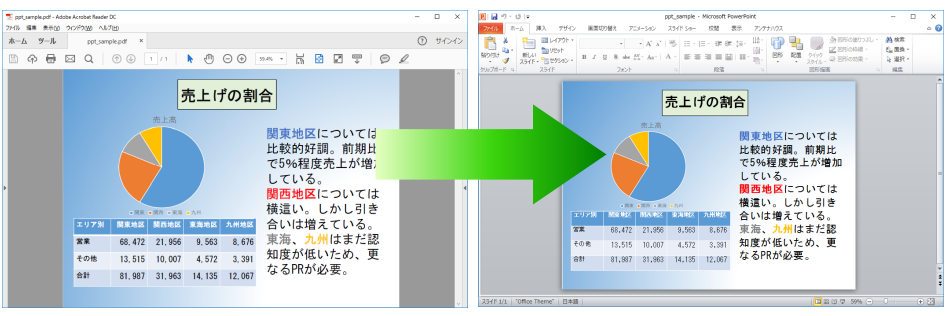
『瞬簡PDF 変換 11』の優れた変換精度をご確認ください。
PDFのテキスト・画像など内部情報を解析し、Wordの文字・段落・表書式や画像に変換します。段落への変換を優先するため、変換結果がWord上で編集しやすくなり再利用の手間を軽減できます。
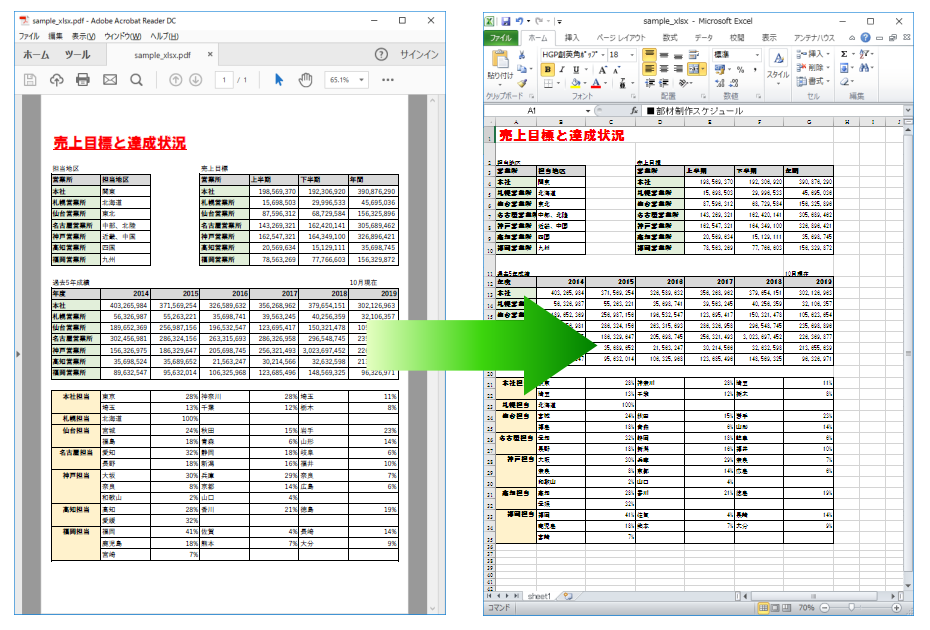
PDFからテキストと線分の位置情報を解析して、Excelのセル書式に再現します。セルの位置・大きさ・テキストの配置など、元の表イメージに近い変換結果を得ることができます。
PDFの1ページをPowerPointの1スライドに変換します。レイアウトを優先した変換で、元のプレゼンテーション・データを無駄なく再利用できます。