PDFの内容をデータソースとして活用、正確かつ省力でPDFデータ抽出

PDFファイルからデータを抽出する要件をクリアしたい
PDFファイルは環境に依存せず閲覧することができる有用さと、簡単には改ざんされにくいというセキュリティの高さから利用されているケースが多数あります。
アプリケーションにも依存しないという性質から、昨今のクラウドサービスでも出力する方式としてはPDFが多く選ばれます。
PDFは閲覧に優れるが解析は難しい
PDFは、閲覧し印刷する用途については非常に有用ですが、データを取得し解析するとなると標準の手順や一般的なソフトウェアだけで実現することは難しいです。
コピー&ペーストである程度取得できることもできますが、たとえばExcelのような表組がPDF上で表現されていたとしても、単純なコピー&ペーストで表組はコピーできません。
もちろんPDF上のデータを手作業で入力し直すという作業は、人手がかかりすぎるうえに誤入力のリスクも考えられるので、定型的な作業であるなら、自動化できるような仕組みを導入することが適切です。
PDFには便利な統計情報が含まれることがあり、活用シーンが多い
事務分野においてはペーパーレスが進み、紙ではなくPDFで直接見積書や積算書をやり取りするケースも増えているのではないでしょうか。
近年だと電子帳簿保存法への対応や、事務作業者がテレワークを実施するなども増えてくると、さらに今後は紙ではなく電子データ、それも環境に依存しないPDFを中心として多くの情報をやり取りすることが増えることが考えられます。
統計情報もCSVやExcelで保存または公開している場合は加工や解析がしやすいですが、PDFだけで公開されている場合はデータ化することが非常に難しくなります。
もしPDFに記録された表組のデータや、保存された情報を抽出できる仕組みがあれば、現在手作業で行っている場合や、作業量的に現実的ではないかと考えていた抽出・分析作業が実現できることで、より情報を迅速・正確に取り扱うことができるのではないでしょうか。
PDFXMLでPDFの解析・抽出を実現
![]()
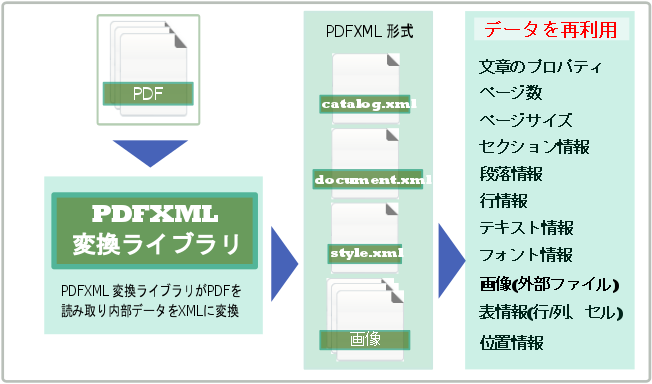
『Antenna House PDFXML変換ライブラリ(PDFXML)』は、PDFを読み込んで内部のテーブル、テキスト、図をXML形式に変換することができるライブラリです。『PDFXML』を使うことでPDFデータに含まれているデータを抽出し様々な用途に活用することができるようになります。
『PDFXML』は、WindowsまたはLinux環境において、コマンドラインインターフェイスや、組み込み用C++インターフェースを利用することが可能です。
プログラミング環境だけではなく、コマンドラインインターフェイスを、PHPやPythonなどから呼び出しとして活用するほか、タスクスケジューラによる定期実行、RPAによる事務処理の自動化など、幅広く活用することが可能です。
具体的な利用シーンや『PDFXML』の仕組みについては、以下で詳しくご説明します。
PDF内の表組をデータソースに使う
『PDFXML』では、PDFの内部データを読み取りXMLへ変換することができます。XMLにすることによって、PDF内部の情報を活用することができるデータへと再利用することが可能です。
『PDFXML』で抽出できるのは、PDFの文書、文書内のページ数、ページサイズ、セクション情報、フォント情報、画像、位置情報といった情報です。 この中でも特に活用されている機能は、PDFに保存された表組の情報を抽出しデータソースとして使う事です。
『PDFXML』から直接データベースにデータを投入できるわけではありませんが、XMLにすることでテーブルの表構造をテキストベースで取得することができます。テキストベースで取得できれば、別のツールやプログラムを使い加工することでデータベースへのインポートを行うことも可能となります。
XML形式は定型的なフォーマットの為、PDF側のフォーマット自体があらかじめ想定できていれば、加工によりCSVなどのより汎用的に取り込めるデータ形式に変換することもできます。
具体的なPDFファイルの変換結果サンプルは弊社公式サイトにて公開していますので、ぜひご参考ください。
PDF内の情報の応用を活用する機能(抽出・解析)
『PDFXML』はデータの抽出の中でも、特に帳票データを抽出しデータソースとして使う用途として活用されていますが、それ以外にもXMLデータにすることで実現できる機能例がありますので、下記に紹介いたします。
もし、以下のような用途で課題を抱えている場合はぜひ『PDFXML』の導入を検討してみてください。
PDF文書プロパティを取得
PDFの文書プロパティをXMLとして取得することができます。
例えば、多数のPDFファイルに対してインデックス情報を集約し目録としてまとめるといった用途に使うことができます。個別で作成したPDFに関する情報をXMLで集約し、ページ数や段落情報から目次を作成するといったことも可能です。
数年分のデータが格納された1つのPDFファイルから、文字列に含まれた日付を取得し、どのページからどの期間の情報があるかといったことも取得するための元データをテキストとして取得できます(実際に目次のように表現したりするためには、さらにXMLデータを解析したり変換するためのツールが必要となります)。
PDFに使われているフォント情報やテキスト情報を取得することで、フォーマットを統一するための情報を収集することもできます。

PDFに保存された画像の抽出
PDFに保存されている画像を外部ファイルとして抽出することができます。
例えば、特定の保存場所にPDFを置き、コマンドラインインターフェイスをスケジュールで呼び出すことによって定期的にPDFファイルをXMLに変換することができます。
『PDFXML』自体には変換した画像を任意のフォルダに移動する機能はありませんが、XML変換先から画像ファイルを拡張子で認識し、さらに別フォルダへ移動するといったバッチ処理を用意することで、PDFファイルから画像ファイルを抽出するというタスクを自動化することができます。
PDF文書の差分比較
XMLにすることで、PDF文書の差異をテキストレベルで比較することが可能です。
具体的には、XMLに変換することでPDFの構成が複数のXMLとなります。構成要素を示すカタログXML、フォントなどのレイアウト情報を示すスタイルXML、そして実際のドキュメント情報を格納しているドキュメントXMLなどからなります。
レイアウトの差分であればスタイルやカタログXMLを新旧比較することで構成の変更が検出できますし、ドキュメントXMLをDIFF比較することでドキュメント自体の差異分析ができるようになります。
『PDFXML』自体にDIFF機能は搭載していないため、各種新旧比較のツールを使用することとなります。テキストベースの比較であれば正確に新旧比較ができるため、外部で作成されたドキュメントの新旧比較はもちろん、自社内での作成でも更新が適切に行われているかのチェックツールとして活用することが可能です。

まとめ
『PDFXML』について、ご紹介しました。PDFをデータソースとして活用することや、解析に利用できるようになることで、人力で行っていた作業の省力化や自動化を行う事が可能となります。自社業務の効率改善にぜひご検討を頂ければと思います。
また、アンテナハウスでは『PDFXML』以外にもPDFの変換やオフィス文書系ドキュメントの活用に役立つ多くのサービスやソリューションを提供しております。
もし電子ファイルに関する何らかの課題をお持ちの場合、解決にお役立てできるソリューションをご提供できると思いますので、ぜひ弊社窓口までご相談ください。
- 電子メール
- sis@antenna.co.jp