
自分でPDFを書いてみよう!
書いてわかるPDFフォーマット ~ファイル構造編~
更新日:

このページの目的
PDFファイルを普段利用する機会は多いが、フォーマットについての分かりやすい情報が少ないので、その中身は良く分からないという方は多いでしょう。
ここでは、PDFファイルのフォーマットの構造や、フォーマットの理解に必要な基本的な概念について解説します。
この記事は、2022年5月24日に行われた「ちょっと一息・アンテナハウスウェビナー」の内容をもとに、Webページとして適切にするように変更を加えたものです。ウェビナーの録画はYouTubeのアンテナハウスPDFチャンネルで公開されています。次からご視聴いただけます。

基本となるオブジェクト
はじめに、基本となるオブジェクトについて説明します。
オブジェクトの種類

基本のオブジェクトには、真偽値、数値、文字列、名前、それから空を表すヌルがあります。数値には整数と浮動小数があり、文字列にはそのまま表記するリテラル文字列と、16進で表記する文字列の2種類があります。

それから辞書です。辞書は名前とオブジェクトのペアで非常によく使われるものです。入れ子も可能になっていて、Typeという名前でその種類を表すことがあります。配列はオブジェクトを並べたものです。

ストリームは辞書にデータを加えたものです。例えば画像のビットマップデータと画像のサイズの情報といったような構造を表すのによく使用します。
ストリームはデータの部分の形式を指定できるようになっており、圧縮方式などを指定することが多いです。例えばZIPファイルやJPEGの圧縮方法などを指定できます。
オブジェクトの種類は、基本的には以上です。
オブジェクトを使用するには
オブジェクトを使用するときには、オブジェクト番号と世代という番号をつけて定義をします。定義したオブジェクトは複数の場所から次の図の例にある「12 0 R」というような形式でオブジェクト番号と世代を指定して参照できます。

オブジェクトにはその場所で直接定義する直接オブジェクトと、参照を示す間接オブジェクトという区別があります。
PDFファイルの物理構成
次に、PDFファイルの構造についてご紹介します。
PDFファイルを構成する4つの要素
PDFファイルは次の図に示すように上からヘッダ、ボディ、クロスリファレンス、トレーラーという4つのパートに分かれています。

ヘッダ、ボディ
ヘッダにはPDFのバージョン番号が書かれています。バージョンによって使用できる機能が変わります。ボディにはオブジェクトの定義が並んでいます。
クロスリファレンス
クロスリファレンスは特定の番号のオブジェクトがファイルの中のオフセットのどの位置にあるかということを示す構造です。次の図の下の部分がクロスリファレンスです。
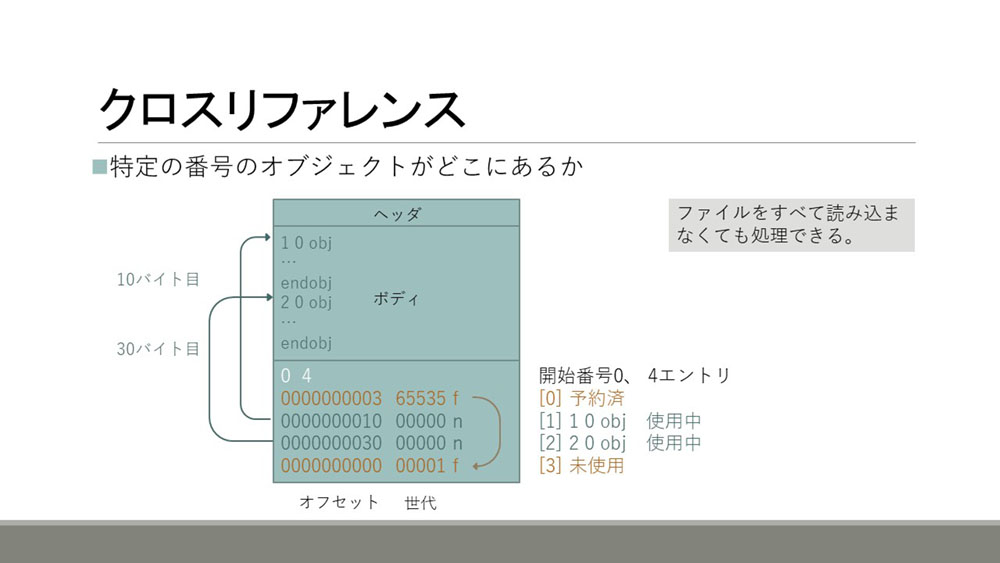
ここでは0番1番2番3番という4つのオブジェクトのフィールドが書いてあります。0番目は予約されているので通常必ずあるものです。
オブジェクトごとに3つフィールドがあり、最初のフィールドがオフセットを表します。2つ目は世代を表していて、3つ目のフィールドのnは使用中ということを表します。
このような構造を使うことでファイル全体をすべてメモリに読み込む必要がなくなります。逐次ディスクから読み出せばよくなりますので、大きいファイルでもメモリの消費を抑えることができるという利点があります。
トレーラー
トレーラーはファイルの一番最後に位置しており、辞書の形式になっています。

一番重要なのはRootのキーです。ここで示されているオブジェクトからPDFファイル内のデータをいろいろ辿っていく形になっています。その下にはstartxref(スタートクロスレフ)にクロスリファレンスのフィールドが始まるオフセットが書かれています。
通常PDFファイルを解析するときはこの1番下のstartxrefからクロスリファレンスのフィールドを読み取り、次に各番号のオブジェクトを辿っていきます。
PDFファイルの論理構成
続いて、文書データをどのようにしてオブジェクトで表すのかということを説明します。
PDFのオブジェクトの表現方法
PDFのオブジェクトは辞書やストリームを使って表現をします。例えば文書カタログ、ページツリー、ページは辞書のかたちで表現し、ページのコンテンツはストリームのかたちで表現します。その他にもイメージやフォントなど様々な種類の辞書やストリームがあります。ここでは主なものを紹介します。
文書カタログ
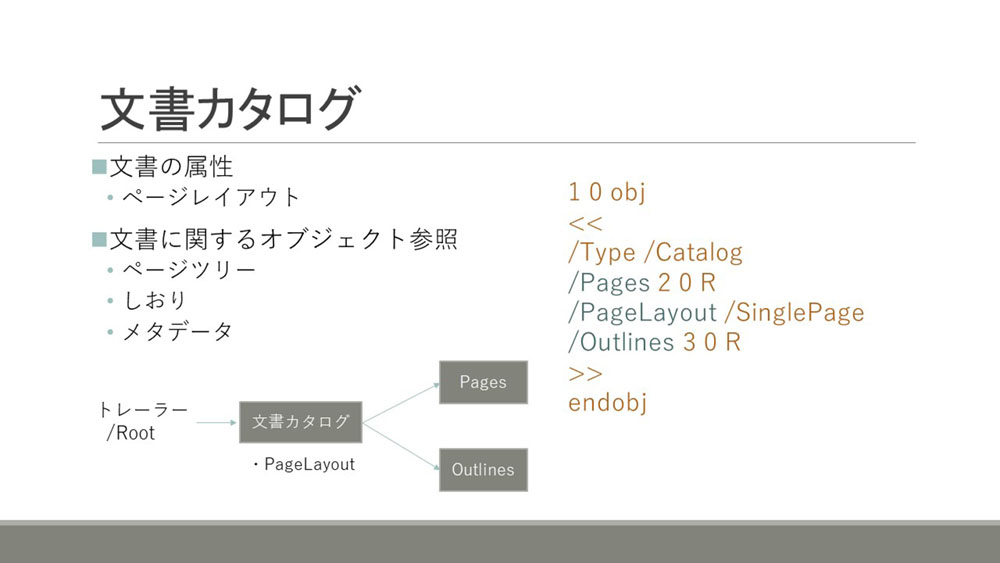
文書カタログは名前の通り文書に関する属性や、様々な情報へのカタログになっています。
例えば属性やページレイアウト、あとはオブジェクトの参照としてはページツリー、しおりのデータ、メタデータといった構造への参照を辿れるような形になっています。文書カタログはトレーラーのルートキーから辿ることができます。
ページツリー

ページツリーはページの階層をツリー状のデータ構造で表したものです。
一番末端はPageという辞書、その中間はPagesという辞書になっています。ツリー状の構成はそのページ数が大きい場合に辿りやすくするのと、ページ共通の属性を効率よく定義できるようにする意味合いがあります。
ページ辞書、ページコンテンツ

ページ辞書にはページの用紙サイズ、コンテンツ、それからフォントや画像などのリソース辞書が定義されています。ページのコンテンツにはページ記述用の命令の列が書かれています。
ページ記述の基礎
次に、ページの中身の記述方法についてもう少し詳しく説明します。
グラフィックオブジェクト
ページの記述はグラフィックオブジェクトを使って行います。グラフィックオブジェクトには、パス、テキスト、イメージの3つの種類があります。
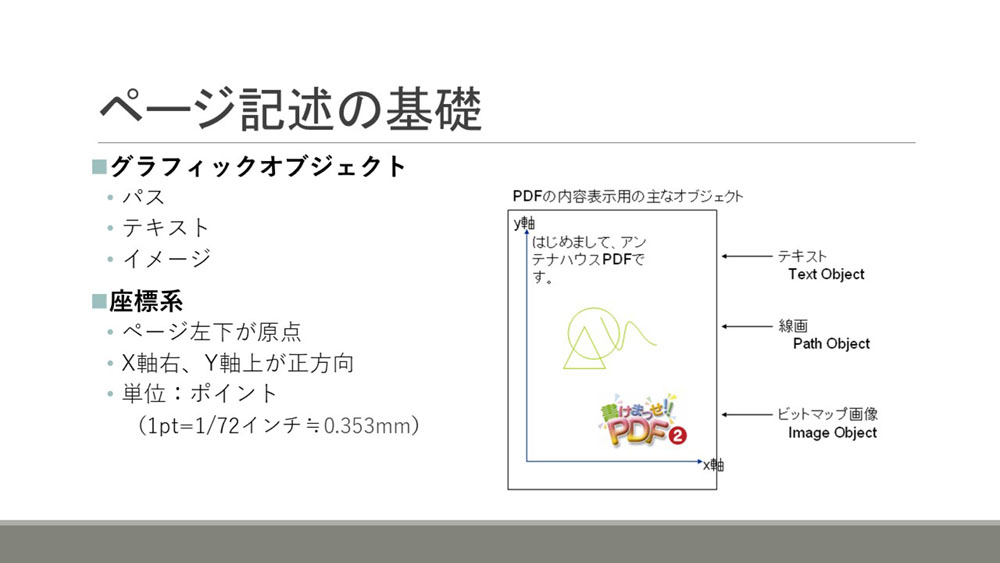
PDFのページの座標系は、ページ左下が原点で、X軸は右方向、Y軸は上方向が正になります。単位はpt(ポイント)で、1ptは1/72インチです。
パスの記述
パスの記述には、パスの形状を定義するパス構築オペレータと、線を引く、塗りつぶすといった描画方法を指定するパス描画オペレータの2種類のオペレータがあります。下の図の例にあるように、矩形や曲線などを描くことができます。
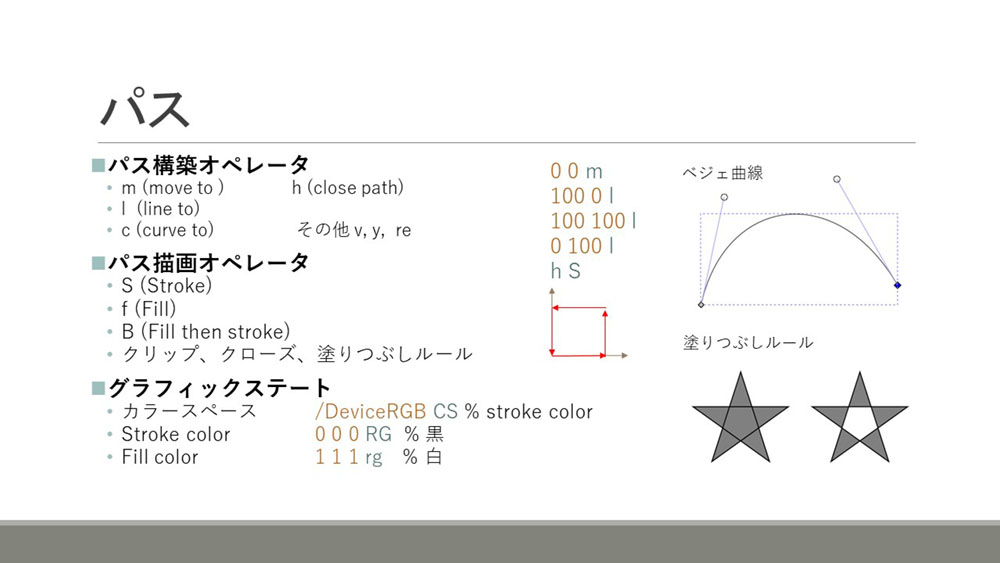
グラフィックステートは、カラースペースや、線の色といったグラフィックの状態を管理します。
テキストの記述
テキストは開始、終了のタグでくくって記述します。テキストの記述には、フォント指定や、行の開始、文字コードを指定してテキストを描画するオペレータなどがあります。

テキストを記述するときは、フォントを指定する必要があります。フォントについてはフォントの辞書という構造があり、そちらの辞書を使って定義します。

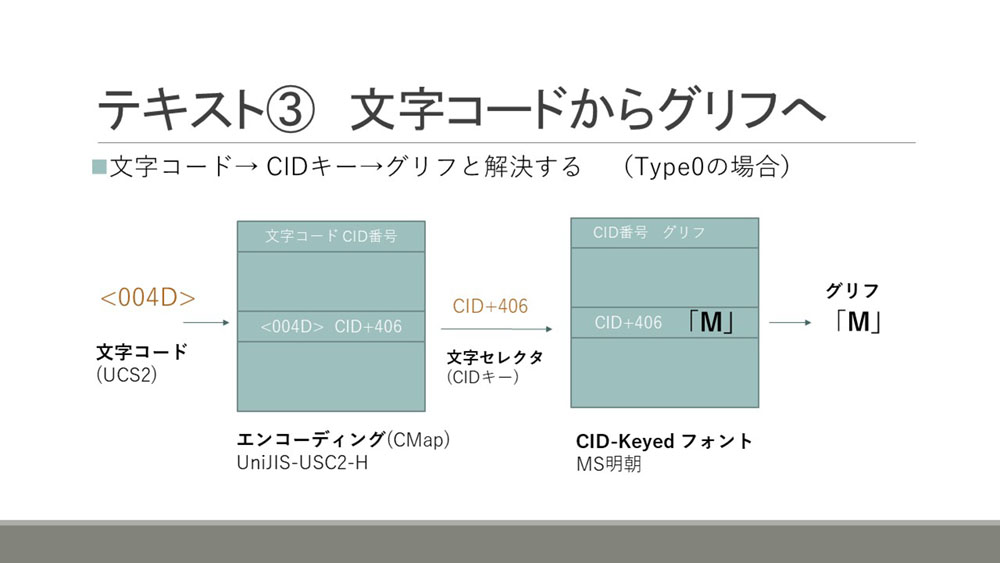
フォントについてはいろいろ形式があり複雑なので概要になりますが、エンコーディングと呼ばれるコンテンツの文字コードをCIDキーという形式に対応付けるような構造や、フォントのタイプ、文字集合、フォント記述子というような構造を、辞書を使って記述していきます。
大まかな仕組みとしては、コンテンツにある文字コードからエンコーディングを使ってCIDキーという文字を表すキーに変換し、その中からフォントの中のグリフを指定するというような構造になっています。
まとめ
PDFファイルのフォーマットの構造や、フォーマットの理解に必要な基本的な概念について解説しました。
普段利用する機会は多いPDFファイルですが、その中身について触れる機会はあまりないかもしれません。今回紹介した内容は基本的なもののみですが、PDFのファイル構造を理解するにあたっての導入となればと思います。
ウェビナー動画のご紹介
ウェビナー動画では、本記事にて解説した内容を踏まえて、実際にテキストエディターを使用して2種類のPDFファイルを自作するデモをご覧いただくことができます。こちらも併せてご参照いただくことで、皆様が少しでもPDFの構造について具体的なイメージを持っていただけましたら幸いです。
製品のご紹介
今回ご紹介したウェビナーではPDFの中身を知っていただくという目的で、実際に手で書いてみるということを行っていますが、実際のPDFを手で書くのは難しいです。
アンテナハウスでは、PDFに関するライブラリを開発しておりますので、こちらもぜひご参照ください。また、PDFに関する案件のご相談もお受けしておりますので、お気軽にお問い合わせください。
Webページの内容、ウェビナーや関連製品についてのお問い合わせはページ下部のお問い合わせよりお送りください。