
プログラマーから見たPDFファイル
更新日:

このページの目的
プログラマーは、クライアントから提供されたPDFファイルで、その要求を実現させようとしたとき、PDFのどんなところを見ているのでしょうか。このページでは、ちょっと珍しい視点でPDFファイルを解き明かしていきます。
自分でプログラムを書いてPDFファイルからテキストデータを取り出したいという人も、ぜひご一読ください。
はじめに
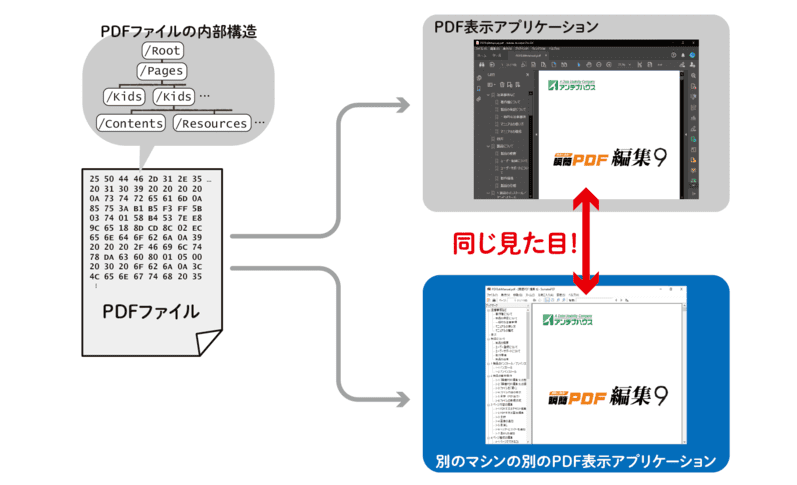
PDFファイルをクリックすると、あたかも紙に印刷したかのように、どんなマシンでも同じような見た目で文章や画像がディスプレイに表示されます。
この単純な事実は、日常的にPDFファイルを利用していると当たり前に感じられるかもしれません。しかし、よくよく考えると驚くべきことです。
いったい、どのような仕組みがあれば、「過去から現在に至るさまざまな種類のコンピューターで見た目を変えずに同一の紙面を再現する」という目的を達成できるでしょうか? そのような仕組みがけっして自明なものでないことは、コンピューターに少し詳しい人であれば容易に想像できると思います。
PDFファイルの中身には、この「多様なマシン環境で文書の同一の見た目を再現する」という目的にとって必要な要素がぎっしり詰め込まれています。 この目的に特化して開発されたファイルフォーマットと、それを解釈して表示するための専用アプリケーションが、「PDF」という技術のもっとも基本的な枠組みであるといえます。
PDFファイルをプログラムで自動処理したい
先ほどはPDFという技術の目的を次のように要約しました。
- 多様なマシン環境で文書の同一の見た目を再現すること
しかし、自分でプログラムを書いたり、Unixツールを組み合わせたりして複数のファイルを一括処理することに慣れている人であれば、これとは違う目的でPDFファイルを利用したいと思ったことがあるでしょう。 たとえば以下のような目的でPDFファイルを使いたいと思っている人も少なくないと思います。
- PDFファイルを他の形式の文書へと変換するプログラムを書きたい
- PDFファイルで提供されるデータを統計処理のためのソースとして利用したい
- 複数のPDFファイルをgrepなどのツールで全文検索したい
これらの目的にとっては、PDFの本来の目的である「見た目の同一性」はあまり重要ではありません。 むしろ、表示のためのアプリケーションを立ち上げずにPDFファイルから「テキストデータ」(下記の注釈を参照)を効率よく取り出せる必要があります。
PDFファイルの中には、いかにも上記の目的で利用可能なテキストデータが含まれているように見えるので、汎用のプログラミング言語で直接PDFファイルを開いてテキストデータのみを処理することもできそうに思えます。
しかし、実はPDFファイルからテキストデータを取り出すのは意外と大変です。 そこで本稿では、それがなぜ大変なのか、実際にやるとしたらどういうアプローチが可能なのかについて、主にプログラミングの経験がある方向けに説明します。
本稿では「テキストデータ」という用語を、文字で表せる情報をコンピューターで扱うときの一般的なデータ表現の意味で使っています。
具体的なデータ表現は問いませんが、「人間にとって意味があるUnicode文字の並び」(をコンピューター上のバイト列として符号化したもの)だと思ってください。 汎用のプログラミング言語で文字列として処理できたり、grepをはじめとする基本的なUnixツールへの入出力に使えたりするデータ、と思ってもかまいません。
PDFファイルにはテキストデータそのものは含まれていない
テキストエディタや汎用のプログラミング言語でPDFファイルを開いても、そのままでは意味のあるデータとして利用できません。
通常、PDFファイルはバイナリデータであり、仕様に従ってバイト列を読み取ることで構造を取り出す必要があるからです。 幸い、PDFの仕様はISO 32000-1:2008としてすべて公開されており、それに従ってPDFファイル内のバイナリデータを解きほぐすプログラムを書くこと自体はそれほど難しくありません。
バイナリデータとしてのPDFファイルがどういう構造になっているかについては、日本語の解説書なども出ているので、本稿では触れません。 本稿で扱うのは、PDFファイルの中のバイナリデータを解析してみたものの、そこからテキストデータをうまく取り出せず、そういうものかと思って断念した経験があるような方向けの話題です。
しかし、PDFファイルの構造を解きほぐしても、それだけではテキストデータを得られません。 それどころか、PDFファイルによっては「テキストデータを構成する文字」がそもそも含まれていないこともあります。
その代わりPDFファイルには、「どのフォントのどの文字を画面のどこに配置すればいいか」という情報が含まれています。 この情報さえあれば、「多様なマシン環境で同一の見た目を再現する」というPDFの目的にとっては十分だからです。
言い換えると、PDFファイルの表示にとって必要なのは「絵としての文字」であり、「テキストデータを構成する文字」ではないと言えるでしょう(下図参照)。 逆に、PDFファイルの表示にとってテキストデータは不可欠なものではありません。 PDFファイルからテキストデータを取り出すのが意外と難しいのは、単純に言えばこの点が主な原因です。

それでもPDFファイルからテキストデータを取り出したい
PDFの表示には不要なテキストデータですが、表示のためのアプリケーションがまったくテキストデータを必要としないわけではありません。
表示されている文字を選択してクリップボードなどにコピーしたり、ファイル内を検索したりといった機能には、テキストデータが必要になります。 そのため、PDFの仕様にも「テキストデータの取り出し」について説明されたセクションがあります(ISO 32000-1:2008のセクション9.10)。
ただし、このセクションの情報は、「PDFファイルをどういう手順で読み込めばテキストデータが得られるか」を説明するものではありません。 あくまでも「表示用アプリケーション向けの情報が取り出せる状態になった後」で、そこからテキストデータを取り出すためのアプローチについて解説したものです。
では、実際にプログラムを書くなどしてテキストデータを取り出すとしたら、どういった手順をとればいいでしょうか? さまざまなアプローチが考えられると思いますが、ここではPDFファイルの仕組みを簡単に説明しつつ、その手順の一例を紹介します。
1. バイナリデータを解析してコンテントストリームを探す
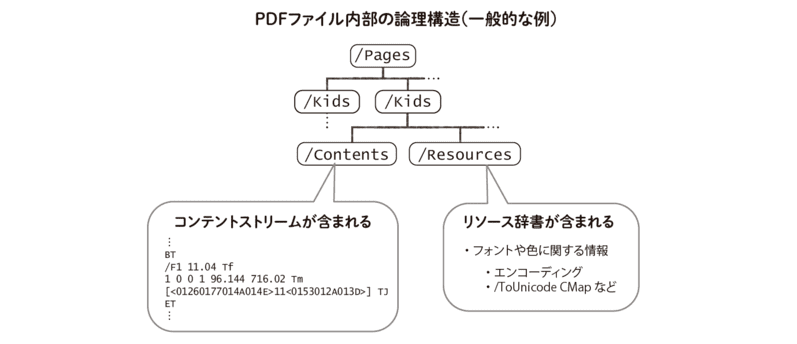
まずは、バイナリデータを解析し、PDFファイルを表示したときにページになるデータ構造を探し出します。 このデータ構造は「コンテントストリーム」と呼ばれ、PDFファイルのあちこちに分散して格納されています(先に触れたように、本稿ではPDFファイルからコンテントストリームを探し出す方法については割愛します)。
「テキストデータ」と紛らわしいですが、PDFの仕様などでは、あるページに表示される文字(つまり「絵としての文字」の並び)のことを単に「テキスト」と呼んでいます。 コンテントストリームからページ上に配置されるテキストを読み取り、それをテキストデータとして解釈しようというのが、以降の基本的な方針です。
なお、PDFファイル中のコンテントストリームは通常は圧縮されています。 これを適切なアルゴリズムで解凍するとプレーンテキスト形式のデータが得られます。 以降では、このプレーンテキスト形式にしたデータのこともまた「コンテントストリーム」と呼ぶことにします。
さらに暗号化PDFファイルの場合は、圧縮された状態を解凍する前に、まずは暗号化アルゴリズムによる復号も必要になります。
2. コンテントストリームを読む
コンテントストリームは、「PDFオペレーター」と呼ばれる命令と、その引数によって構成されています。 命令と引数で構成されることから想像できるように、コンテントストリームから必要な情報を適切に取り出すには、パーザーを書いてスタックマシンに相当する仕組みを実装する必要があります。
PDF表示アプリケーションでも、画面上に表示するページを組み立てるために、PDFオペレーターとその引数を解釈して「どのフォントのどの文字を画面のどこに配置すればいいか」などを認識するようになっています。 次項で説明するように、それと同じような仕組みがテキストデータを取り出すにも必要になるということです。
とはいえ、画像を配置するためのPDFオペレーターや色の管理をするためのPDFオペレーターは無視できるので、そのへんは楽ができます。 コンテントストリームからテキストデータを取り出すために最低限実装が必要になるPDFオペレーターは以下の4種類です。
- コンテントストリームにおけるテキストの存在を示すBTオペレーターとETオペレーター
- ページ上でのテキストの位置を決めるためのTmオペレーターやTdオペレーターなど
- フォント選択用のTfオペレーター
- テキスト描画用のTJオペレーターやTjオペレーターなど
3. テキスト描画用オペレーターの引数からテキストデータを手に入れる
プレーンテキスト形式にしたコンテントストリームをエディタなどで眺めていると、TJオペレーターやTjオペレーターの引数が「いかにもテキストデータっぽい情報」に見えます。
しかし、この引数をそのまま読んでもテキストデータとしては使えません。 「コンテントストリームからTJ/Tjオペレーターなどを正規表現で探して取り出せばテキストデータが得られるだろう」とはいかないのです。
なぜそれができないのでしょうか。主な理由は以下の3つです。
- 引数がどういう書式およびエンコーディングで格納されているかが、PDF生成ツールの実装やフォントの種類によってまちまち
- 引数から直接わかるのは、あるフォントから絵としての文字を描くための情報を探し出す方法であり、テキストデータとは限らない
- コンテントストリーム内でのTJ/Tjオペレーターなどの位置関係だけでは、テキストデータとしての順序はわからない
引数がどのように格納されているか
1つめは、TJ/Tjオペレーターの引数をどうやって読むか、という問題です。 仕様上、テキスト描画用のPDFオペレーターの引数には「リテラル文字列」もしくは「16進文字列」が使えて、これらは書式がまったく異なります。
さらに、それらの文字列をどのようなエンコーディングで読み取ればいいかはフォントによって異なります。 場合によっては埋め込まれたフォントの内部まで見てはじめてエンコーディングが判明することもあります。
引数から直接わかるのは、テキストデータとは限らない
2つめは、そうやって読み取った引数が一般にはテキストデータそのものではない、という問題です。 特に日本語フォントでは、この引数が「そのフォントの中で文字を探し出すための識別子」でしかない場合が多々あります。
テキストデータを得るには、それがどのUnicode文字に対応しているかを、PDFファイル内外の別の場所にある情報を参照して調べることになります。 多くの場合は「/ToUnicode CMap」と呼ばれる対応表がPDFファイル中に含まれているので、この情報を使って識別子からUnicode文字を変換します。
なお、エンコーディングや/ToUnicode CMapはコンテントストリームだけからはわかりません。 コンテントストリームには「その箇所で利用されているフォント」だけがTfオペレーターとして指示されています。 その指示をもとに、PDFファイル内の別の場所にある「リソース辞書」と呼ばれるデータ構造を見て、エンコーディングや/ToUnicode CMapを探り当てます。
フォントやエンコーディングによってはコンテントストリームからテキストデータが直接得られる場合もありますが、「そういう場合である」という事実を知るのにも、やはりTfオペレーター経由でリソース辞書を調べなければなりません。
コンテントストリーム内でのテキストデータとしての順序
3つめの問題は、私たちがPDFファイルからテキストデータを取り出すときには「表示されたPDFファイルを人間が読む順番」であることを期待するけれど、コンテントストリーム内でテキスト描画オペレーターがそのように並んでいるとは限らない、という意味です。
コンテントストリームで隣り合っているテキストが、出力するテキストデータでも隣り合っているべきなのか、間に十分なスペースや改行がある別の単語を構成しているのか、そういう状態を判別できない限り使えるテキストデータは手に入りません。
人間がPDFファイルの表示を読んだときに期待するような順番や形でテキストデータを手に入れるには、TdやTmといったオペレーターの情報を読み取ってページ上の配置を計算し、それを参考にしながら空白や改行を挿入して文字を連接したり、もっと大きく順番を入れ替えたりする必要があるのです。
記事の前のほうで、PDFの仕様に「テキストデータの取り出し」についてのセクションがあると書きました。 仕様のこのセクションで示されているのは、上記の2つめの理由に対する解決策の一部になります。
コンテントストリームからテキストデータを取り出す実例
「コンテントストリームを読み、Unicode文字を手に入れて、それを期待するテキストデータにする」のが実際にどのような作業なのか、ここでは3つの異なる環境で作られたPDFファイルを例に紹介します。
いずれも筆者の環境で生成したPDFファイルのコンテントストリームによる実例です(環境やバージョンによって実際に生成されるコンテントストリームの内容は異なります)。
各PDFオペレーターの詳しい説明は割愛します。「後置記法なので引数が前に置かれる」という点にだけ注意してください。 また、フォントの情報の読み方についても説明を省きます。 なお、実際のコンテントストリームはもっと長いデータですが、BTからETで囲まれた部分がテキスト描画に関係する部分なので、それ以外の部分はすべて省略して示してあります。
1. MS Wordで生成したPDFファイルの例
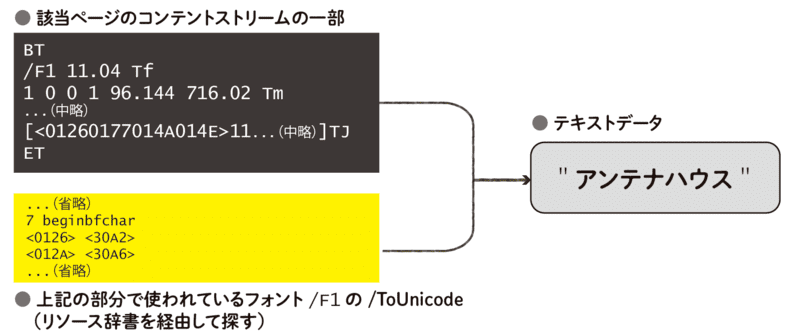
最初の例は、Windows上のMS Wordで生成したPDFファイルのコンテントストリームと、そこからテキストデータを取り出す例です。 PDFファイルから最初のページのコンテントストリームを探し出すと以下のようなデータが含まれていました。
BT
/F1 11.04 Tf
1 0 0 1 96.144 716.02 Tm
/GS10 gs
0 g
/GS11 gs
0 G
[<01260177014A014E>11<0153012A013D>] TJ
ET
すでに説明したように、テキストデータを取り出すには上記のようなコンテントストリームだけでなく、対応するフォントに関する情報も必要です。 上記の例の範囲では、2行目のTfオペレーターの引数を見ることで、/F1という名前で示されているフォントが使われていることが読み取れます。
そこで実際に/F1で示されているフォントの情報を調べると、以下のような情報が得られます。
/Type: /Font
/Subtype: /Type0
/BaseFont: /BCDEEE+UDDigiKyokashoN-R
/Encoding: /Identity-H
/DescendantFonts: 6
/ToUnicode: 23
上記からは、「このフォントはType0という種類で、そのエンコーディングは/Identity-Hであり、さらに/ToUnidode CMapがこのPDFファイル中のに存在して、その参照番号は23である」ことがわかります。
意訳すると、「TJオペレーターの引数(この場合は16進文字列で指定されている)をそのまま2バイト1文字として読み、それをPDFファイル中の23という番号で参照できる/ToUnidode CMapを使ってUnicode文字に変換すれば、テキストデータが得られる」ということです。
ちなみに、参照番号23にあるデータ構造の中身を調べてみると、次のような情報が見つかります。 これが/ToUnidode CMapの実際の姿の例です。
/CIDInit /ProcSet findresource begin
10 dict begin
begincmap
/CIDSystemInfo
<< /Registry (Adobe)
/Ordering (UCS)
/Supplement 0
>> def
/CMapName /Adobe-Identity-UCS def
/CMapType 2 def
1 begincodespacerange
<0000> <FFFF>
endcodespacerange
7 beginbfchar
<0126> <30A2>
<012A> <30A6>
<013D> <30B9>
<014A> <30C6>
<014E> <30CA>
<0153> <30CF>
<0177> <30F3>
endbfchar
endcmap
CMapName currentdict /CMap defineresource pop
end
end
あとは得られたUnicodeの各文字を適切につなげるだけです。 この例の場合は、すべての文字が1つのTJオペレーターの引数になっているので、各文字を単純につなげて最終的なテキストデータとすればいいでしょう。
ただし、TJオペレーターの引数で途中に出てくる「11」は文字ではなく文字詰めに関する情報なので、少しだけ注意が必要になります。
2. wxhtmltopdfで生成したPDFファイルの例
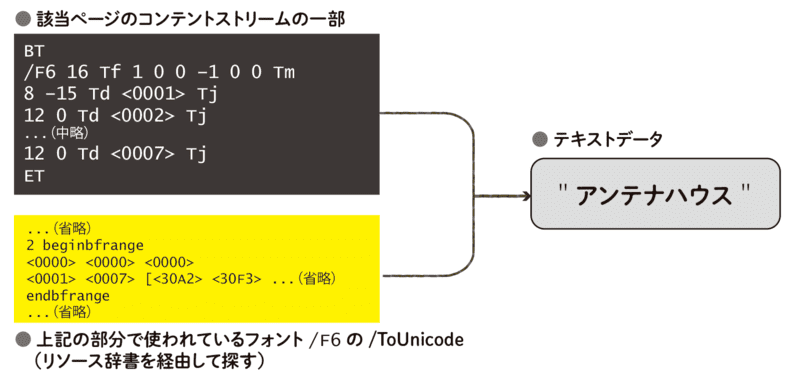
次の例は、wxhtmltopdfというツールで生成したPDFファイルの例です。 やはり環境によって異なりますが、wxhtmltopdfは以下のようなコンテントストリームを生成するようです。
BT
/F6 16 Tf 1 0 0 -1 0 0 Tm
8 -15 Td <0001> Tj
12 0 Td <0002> Tj
12 0 Td <0003> Tj
12 0 Td <0004> Tj
13 0 Td <0005> Tj
14 0 Td <0006> Tj
12 0 Td <0007> Tj
ET
この場合も、まずフォントに関する情報を調べてエンコーディングなどを知る必要があります。 この範囲で使われる/F6というフォントの情報を調べてみると下記のようになっていました。
/Type: /Font
/Subtype: /Type0
/BaseFont: /MSUIGothic??
/Encoding: /Identity-H
/DescendantFonts: 14
/ToUnicode: 15
先のMS Wordの例と同じく、フォントの種類はType0でエンコーディングがIdentity-Hなので、Tjオペレーターの引数(16進文字列)をそのまま2バイトずつ読み、さらに/ToUnicode CMapを使って変換すればテキストデータが得られます。
先の例と異なるのは、テキストデータの配置を読み取るために各行のTdオペレーターの情報を使わなければならない点です。
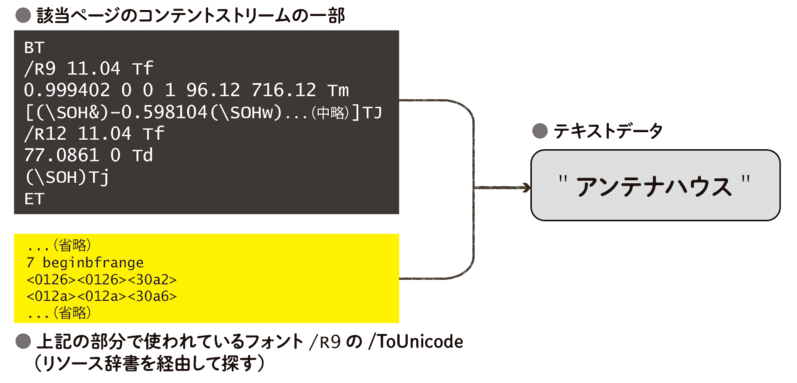
3. Primo PDFで生成したPDFファイルの例
次は、Primo PDFというツールで生成したPDFファイルの例です。 筆者の環境で生成したPDFファイルからは下記のようなコンテントストリームが得られました。
BT
/R9 11.04 Tf
0.999402 0 0 1 96.12 716.12 Tm
[(\SOH&)-0.598104(\SOHw)-0.598104(\SOHJ)-0.598768(\SOHN)10.2773(\SOHS)-0.598768(\SOH*)-0.598768(\SOH=)1000]TJ
/R12 11.04 Tf
77.0861 0 Td
(\SOH)Tj
ET
先ほどまでの例では、TJ/Tjオペレーターの引数の書式が16進文字列でしたが、この例ではTJオペレーターの引数がリテラル文字列になっています(明らかに様子が違うのが見て取れると思います)。
とはいえ、この範囲で使われているフォント/R9の情報を調べると、下記のように/Type0フォントかつ/Identity-Hエンコーディングであることがわかるので、同じようにそのまま2バイトを1文字として読むだけです。
/Subtype: /Type0
/Type: /Font
/BaseFont: /SUMHAC+UDデジタル教科書体N-R
/Encoding: /Identity-H
/DescendantFonts: 10
/ToUnicode: 18
そのうえで、やはり/ToUnicode CMapを使ってUnicode文字に変換すれば、テキストデータが取り出せます。
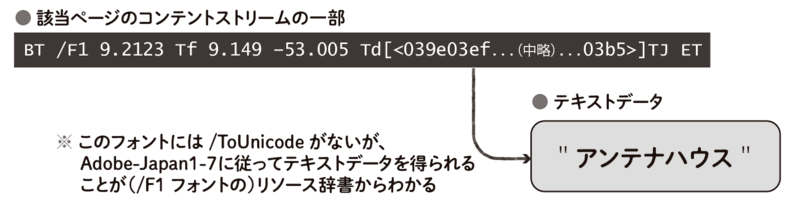
4. dvipdfmxで生成したPDFファイルの例
最後に、/ToUnicode CMapがない場合の例を簡単に紹介だけします。
日本語LaTeX文書からPDFを生成するときにはdvipdfmxというツールが広く使われています。 このdvipdfmxでPDFを生成したところ、以下のようなコンテントストリームが得られました。
BT /F1 9.2123 Tf 9.149 -53.005 Td[<039e03ef03c203c603cb03a203b5>]TJ ET
これまでの例と同様に、リソース辞書からフォント/F1の情報を調べてみると、以下のようになっていました。
/Type: /Font
/Subtype: /Type0
/BaseFont: /JTRZSC+IPAexMincho
/Encoding: /Identity-H
/DescendantFonts: 4
エンコーディングは/Identity-Hであると読めますが、/ToUnicode CMapが見当たりません。 この例の場合には、フォントの種類がType0であることから、「さらに詳しい情報を/DescendantFontsというエントリーの情報をから調べればよい」ということが分かります。
そこで、/DescendantFontsのエントリーを調べてみると、以下のような/CIDSystemInfoという情報が判明します。
/CIDSystemInfo:
/Registry: Adobe
/Ordering: Japan1
/Supplement: 7.0
この例では、この/CIDSystemInfoによって示される「Adobe-Japan1-7」という情報が鍵となります。 Adobe-Japan1-7というのはAdobe社が定める日本語の文字集合の名称であり、その識別子(CIDと呼ばれます)からUnicodeへの対応も公開されているので、それに従ってコンテントストリームを読めばテキストデータが得られます。
ここで紹介した例は、いずれも筆者の環境で各アプリケーションにより作成した実際のPDFファイルのものですが、「各アプリケーションがPDFファイルをこの例のように生成する」ことは意味しません。 利用するフォントの種類やOSなどのさまざまな条件により実際に生成されるPDFファイルの中身は異なることに注意してください。
既存のツールを使う
PDFファイルの構造や、そのストリームでPDFオペレーターがどのように使われているかは、PDF生成アプリケーションの種類や環境によって本当に千差万別です。
PDFはそれなりに歴史が古いフォーマットということもあって、びっくりするくらい多種多様なスタイルで作られたPDFファイルが世界中に大量に存在しています。 それらすべてに対応したテキストデータの読み込みを実現するのが大変であることは想像に難くないでしょう。
率直なところ、PDFファイルからテキストデータを取り出すのに自分でバイナリファイルを読む必要はありません。 PDFファイルからテキストデータを抽出できる既存のツールがいくつか存在します。 ここではオープンソースの実装に絞って代表的なものを2つ紹介します。
多くのPDFファイルはpdftotextを使えば十分な出力が得られるでしょう。 おかしなところで改行が入るといった場合には、layout
オプション(表示アプリケーションでの見た目に近い形に整形してテキストデータを出力する機能)を使うとうまくいくこともあります。
ただ、個人的な経験ではテキストデータとしての使い勝手はむしろ悪くなる場合が多いので、PDFファイルに応じていろいろ使い分けてみるのが現実的です。
どうしても満足のいく結果が得られない場合には、自分で対象のファイルに特化したテキストデータ抽出プログラムを書いてみてもいいかもしれません(そのときにこの記事が多少なりとも参考になれば幸いです)。
アンテナハウスからもテキストデータ抽出のためのツールが販売されています。 PDFは主な仕様を理解するだけでも大変なフォーマットなので、本気で重い業務でPDFからのテキストデータの抽出が必要という場合には、プロに相談するのがもっとも効率的かもしれません。