/*
Antenna House PDF Tool API V7.0
C++ Interface sample program
概要:テキスト抽出
Copyright 2018 Antenna House, Inc.
*/
#include < PdfTk.h >
#include < stdio.h >
using namespace PdfTk;
void extractText(PtlPage& page);
int main(int argc, char* argv[])
{
if (argc < 2) {
printf("usage: ExtractText.exe in-pdf-file\n");
return 1;
}
try
{
PtlParamInput input(argv[1]);
PtlPDFDocument doc;
// PDFファイルをロードします。
doc.load(input);
// ページコンテナの取得
PtlPages& pages = doc.getPages();
if (pages.isEmpty()){
printf("ページコンテナが空\n");
return 1;
}
// 先頭ページの取得
PtlPage page = pages.get(0);
// テキスト抽出
extractText(page);
printf("\n完了!\n");
}
catch (const PtlException &e)
{
fprintf(stderr, "Error code : %d\n %s\n", e.getErrorCode(), e.getErrorMessage().c_str());
return 1;
}
return 0;
}
void extractText(PtlPage& page)
{
// ページサイズ
PtlSize pageSize = page.getSize();
// ページコンテントの取得
PtlContent& content = page.getContent();
// テキスト抽出パラメータ
PtlParamExtractText paramExtractText;
// テキスト抽出する範囲
PtlRect rect(0.0f, 0.0f, pageSize.getWidth()/2, pageSize.getHeight()/2);
//paramExtractText.appendRect(rect); // この行のコメントを外すと矩形領域内のテキストを抽出
// テキスト抽出
PtlParamString text = content.extractText(paramExtractText);
printf(text.c_str());
}


PDF Tool APIサンプルコード:テキスト抽出
指定したPDFからテキストを抽出します。
概要
サンプルコードの概要
指定したページの Content 内のテキストを全て抽出します。
- PtlParamExtractText: テキスト抽出時のパラメータ
- PtlContent.extractText(PtlParamExtractText): テキストを抽出
サンプルコード
/*
Antenna House PDF Tool API V7.0
Java Interface sample program
概要:テキスト抽出
Copyright 2018-2021 Antenna House, Inc.
*/
package Sample;
import jp.co.antenna.ptl.*;
public class ExtractText {
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
if (args.length < 1)
{
System.out.println("usage: java ExtractText in-pdf-file");
return;
}
try (PtlParamInput inputFile = new PtlParamInput(args[0]);
PtlPDFDocument doc = new PtlPDFDocument())
{
// PDFファイルをロードします。
doc.load(inputFile);
try (PtlPages pages = doc.getPages()) // ページコンテナの取得
{
// ページコンテナが空かどうか
if (pages.isEmpty())
{
System.out.println("ページコンテナが空");
return;
}
// 1ページ目の取得
try (PtlPage page = pages.get(0))
{
// テキスト抽出
extractText(page);
}
}
}
catch (PtlException pex) {
System.out.println("PtlException : ErrorCode = " + pex.getErrorCode() + "\n " + pex.getErrorMessage());
}
catch (Exception ex) {
System.out.println(ex.getMessage());
ex.printStackTrace();
}
catch (Error ex) {
System.out.println(ex.getMessage());
ex.printStackTrace();
}
finally {
System.out.println("-- 完了 --");
}
}
public static void extractText(PtlPage page) throws PtlException, Exception, Error
{
try (PtlSize pageSize = page.getSize(); // ページサイズの取得
PtlContent content = page.getContent(); // ページコンテントの取得
PtlParamExtractText paramExtractText = new PtlParamExtractText(); // テキスト抽出パラメータ
PtlRect rect = new PtlRect(0.0f, 0.0f, pageSize.getWidth() / 2, pageSize.getHeight() / 2)) // テキスト抽出範囲矩形
{
//paramExtractText.appendRect(rect); // この行のコメントを外すと矩形領域内のテキストを抽出
// テキスト抽出
String text = content.extractText(paramExtractText);
System.out.println(text);
}
}
}
/*
Antenna House PDF Tool API V7.0
.NET Interface sample program
概要:テキスト抽出
Copyright 2018-2021 Antenna House, Inc.
*/
using System;
using PdfTkNet;
namespace ExtractText
{
class Program
{
static void Main(string[] args)
{
if (args.Length < 1)
{
Console.WriteLine("usage: ExtractText.exe in-pdf-file");
return;
}
try
{
using (PtlParamInput inputFile = new PtlParamInput(args[0])) //元PDF
using (PtlPDFDocument doc = new PtlPDFDocument())
{
// PDFファイルをロードします。
doc.load(inputFile);
using (PtlPages pages = doc.getPages())
{
//ページコンテナが空かどうか
if (pages.isEmpty())
{
Console.WriteLine("ページコンテナが空");
return;
}
using (PtlPage page = pages.get(0)) // 先頭ページ
{
// テキスト抽出
ExtractText(page);
}
}
}
}
catch (PtlException pex)
{
Console.WriteLine(pex.getErrorCode() + " : " + pex.getErrorMessageJP());
pex.Dispose();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
finally
{
Console.WriteLine("-- 完了 --");
}
}
static void ExtractText(PtlPage page)
{
using (PtlSize pageSize = page.getSize()) // ページサイズの取得
using (PtlContent content = page.getContent()) // ページコンテントの取得
using (PtlParamExtractText paramExtractText = new PtlParamExtractText()) // テキスト抽出パラメータ
using (PtlRect rect = new PtlRect(0.0f, 0.0f, pageSize.getWidth() / 2, pageSize.getHeight() / 2)) // テキスト抽出範囲矩形
{
//paramExtractText.appendRect(rect); // この行のコメントを外すと矩形領域内のテキストを抽出
// テキスト抽出
String text = content.extractText(paramExtractText);
Console.WriteLine(text);
}
}
}
}
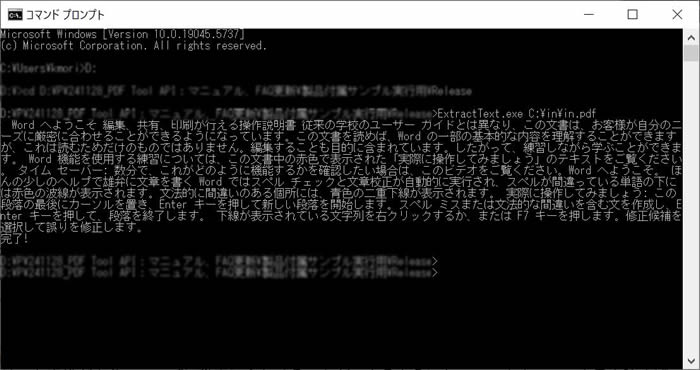
AHPDFToolCmd70.exe -extractText c:\sav\outExtractText.txt -pageNo 0 -d c:\in\in.pdf
実行例
コマンドラインでの実行例
ExtractText.exe C:\in\in.pdf Word へようこそ 編集、共有、印刷が行える操作説明書 従来の学校のユーザー ガイドとは異なり、この文書は、お客様が自分のニーズに厳密に合わせることができるようになっています。この文書を読めば、Word の一部の基本的な内容を理解することができます が、これは読むためだけのものではありません。編集することも目的に含まれています。したがって、練習しながら学ぶことができます。 Word 機能を使用する練習については、この文書中の赤色で表示された「実際に操作してみましょう」のテキストをご覧ください。 タイム セーバー: 数分で、これがどのように機能するかを確認したい場合は、このビデオをご覧ください。Word へようこそ。 ほんの少しのヘルプで雄弁に文章を書く Word ではスペル チェックと文章校正が自動的に実行され、スペルが間違っている単語の下に は赤色の波線が表示されます。文法的に間違いのある個所には、青色の二重下線が表示されます。 実際に操作してみましょう: この 段落の最後にカーソルを置き、Enter キーを押して新しい段落を開始します。スペル ミスまたは文法的な間違いを含む文を作成し、Enter キーを押して、段落を終了します。 下線が表示されている文字列を右クリックするか、または F7 キーを押します。修正候補を選択して誤りを修正します。 完了!
java -jar ExtractText.jar C:\in\in.pdf Word へようこそ 編集、共有、印刷が行える操作説明書 従来の学校のユーザー ガイドとは異なり、この文書は、お客様が自分のニーズに厳密に合わせることができるようになっています。この文書を読めば、Word の一部の基本的な内容を理解することができます が、これは読むためだけのものではありません。編集することも目的に含まれています。したがって、練習しながら学ぶことができます。 Word 機能を使用する練習については、この文書中の赤色で表示された「実際に操作してみましょう」のテキストをご覧ください。 タイム セーバー: 数分で、これがどのように機能するかを確認したい場合は、このビデオをご覧ください。Word へようこそ。 ほんの少しのヘルプで雄弁に文章を書く Word ではスペル チェックと文章校正が自動的に実行され、スペルが間違っている単語の下に は赤色の波線が表示されます。文法的に間違いのある個所には、青色の二重下線が表示されます。 実際に操作してみましょう: この 段落の最後にカーソルを置き、Enter キーを押して新しい段落を開始します。スペル ミスまたは文法的な間違いを含む文を作成し、Enter キーを押して、段落を終了します。 下線が表示されている文字列を右クリックするか、または F7 キーを押します。修正候補を選択して誤りを修正します。 -- 完了 --
ExtractText.exe C:\in\in.pdf Word へようこそ 編集、共有、印刷が行える操作説明書 従来の学校のユーザー ガイドとは異なり、この文書は、お客様が自分のニーズに厳密に合わせることができるようになっています。この文書を読めば、Word の一部の基本的な内容を理解することができます が、これは読むためだけのものではありません。編集することも目的に含まれています。したがって、練習しながら学ぶことができます。 Word 機能を使用する練習については、この文書中の赤色で表示された「実際に操作してみましょう」のテキストをご覧ください。 タイム セーバー: 数分で、これがどのように機能するかを確認したい場合は、このビデオをご覧ください。Word へようこそ。 ほんの少しのヘルプで雄弁に文章を書く Word ではスペル チェックと文章校正が自動的に実行され、スペルが間違っている単語の下に は赤色の波線が表示されます。文法的に間違いのある個所には、青色の二重下線が表示されます。 実際に操作してみましょう: この 段落の最後にカーソルを置き、Enter キーを押して新しい段落を開始します。スペル ミスまたは文法的な間違いを含む文を作成し、Enter キーを押して、段落を終了します。 下線が表示されている文字列を右クリックするか、または F7 キーを押します。修正候補を選択して誤りを修正します。 -- 完了 --
AHPDFToolCmd70.exe -extractText c:\sav\outExtractText.txt -pageNo 0 -d c:\in\in.pdf use time 0.023000s
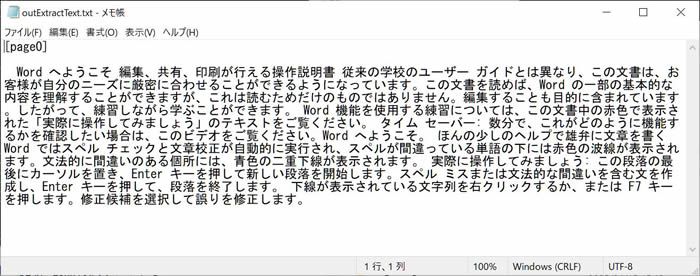
出力結果イメージ
指定したPDFから抽出されたテキストがコマンドラインに出力されます。
コマンドの場合は指定したPDFから抽出されたテキストがテキストファイルに出力されます。